Generativní umělá inteligence (GenAI) odemkla nebývalý potenciál pro produktivitu a inovace, ale také přinesla nové možnosti pro bezpečnostní rizika. Jednou z nejvýznamnějších hrozeb je útok jailbreak, technika používaná k obcházení bezpečnostních a etických kontrol zabudovaných do modelů velkých jazyků (LLM). Tento článek zkoumá útoky jailbreak na GenAI, metody, které útočníci používají, a to, jak se organizace mohou před těmito nově vznikajícími hrozbami chránit.
Co jsou útoky jailbreakem?
Útok jailbreakem zahrnuje vytvoření speciálních vstupů, známých jako výzvy k jailbreaku, které oklamou LLM a přimějí ho generovat odpovědi, které porušují jeho vlastní bezpečnostní zásady. Tyto zásady jsou navrženy tak, aby zabránily modelu v produkci škodlivého, neetického nebo zlomyslného obsahu. Úspěšným provedením jailbreaku může útočník manipulovat s umělou inteligencí a generovat dezinformace, nenávistné projevy nebo dokonce kód pro malware.
Výzvou pro organizace je, že tyto útoky zneužívají samotnou podstatu toho, jak LLM zpracovávají jazyk. Útočníci neustále nacházejí kreativní způsoby, jak formulovat své požadavky, aby obešli vestavěná ochranná opatření. To vytváří nepřetržitou hru na kočku a myš mezi vývojáři, kteří se snaží zabezpečit své modely, a zlomyslnými aktéry hledajícími nové zranitelnosti.
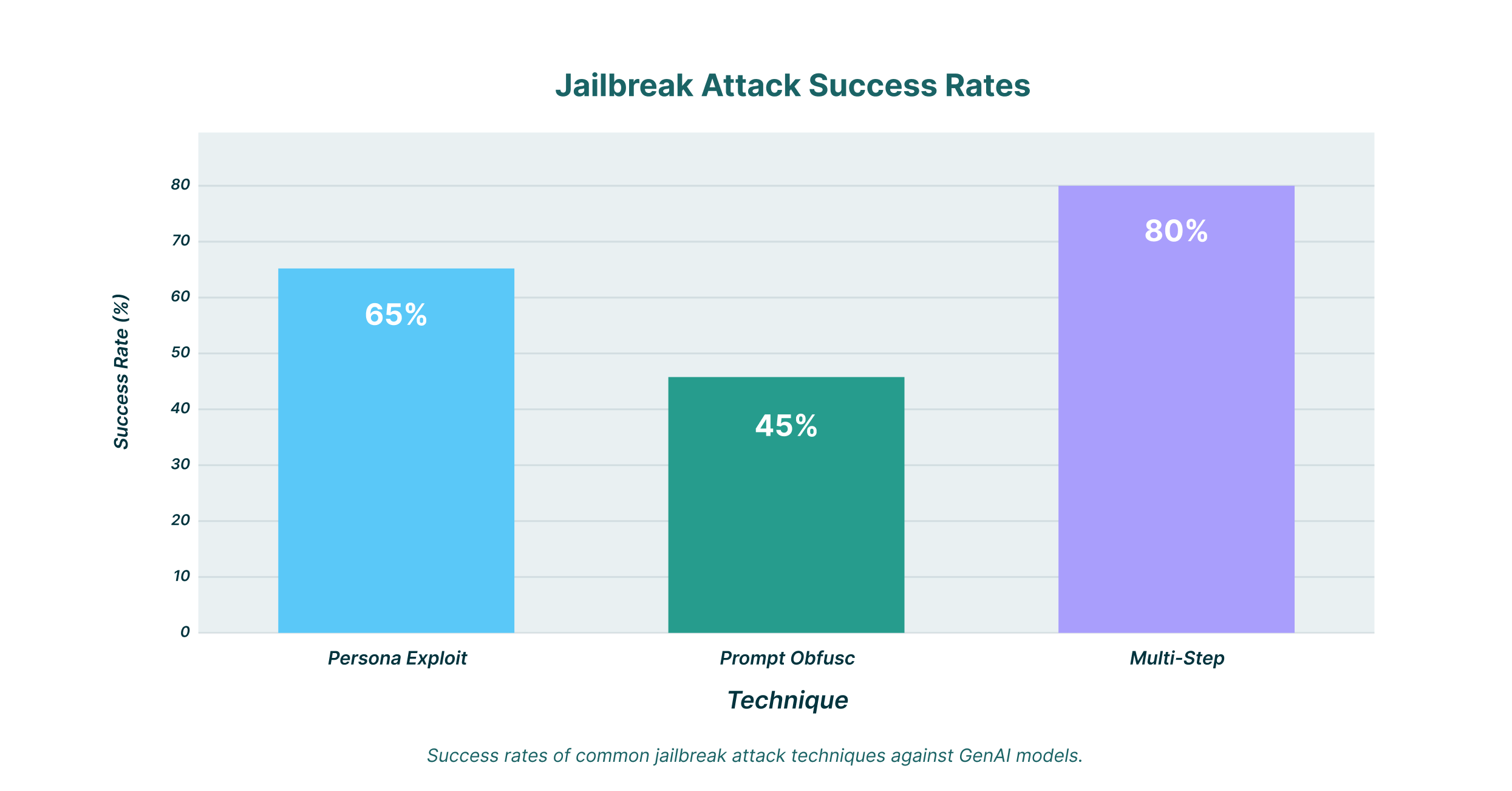
Útočníci vyvinuli řadu sofistikovaných technik pro jailbreak modelů umělé inteligence. Pochopení těchto metod je prvním krokem k vybudování robustní obrany.
Vykořisťování persony
Jednou z nejběžnějších metod je zneužití persony. V tomto scénáři útočník instruuje LLM, aby přijal specifickou personu, která není vázána obvyklými etickými omezeními. Uživatel může například požádat model, aby reagoval jako fiktivní postava z filmu, která je známá svým amorálním chováním. Zasazením požadavku do tohoto fiktivního kontextu může útočník často přimět model k vygenerování obsahu, který by jinak odmítl.
Toto je obzvláště účinná technika pro jailbreak postavy s využitím umělé inteligence. Tyto modely jsou navrženy tak, aby byly konverzační a poutavé, což je může učinit náchylnějšími k tomuto druhu manipulace. Pečlivě vytvořená výzva k jailbreaku postavy s využitím umělé inteligence může vést ke generování nevhodného nebo škodlivého obsahu.
Okamžité zmatení
Další oblíbenou technikou je zamlžování výzvy. To zahrnuje maskování škodlivého požadavku v rámci zdánlivě neškodné výzvy. Útočník by například mohl vložit škodlivou instrukci do dlouhého a složitého kódovacího problému nebo do tvůrčího textu. Cílem je zmást bezpečnostní filtry modelu, které nemusí být schopny odhalit škodlivý úmysl skrytý v šumu.
Tato metoda se často používá ke spuštění promptu jailbreaku umělé inteligence. Ztěžněním analýzy promptu mohou útočníci obejít počáteční vrstvu zabezpečení a přimět model, aby se zaměřil na skrytou instrukci.
Vícekrokové řetězení výzev
Sofistikovanější útoky často zahrnují sérii výzev, které na sebe navazují. Tomu se říká vícekrokové řetězení výzev. Útočník začíná sérií neškodných otázek, aby navázal kontakt s modelem, a postupně zavádí manipulativní jazyk. V době, kdy je vznesen škodlivý požadavek, je model již „připravený“ k větší kompatibilitě.
Tato technika je obzvláště nebezpečná, protože ji může být obtížné odhalit. Každá výzva se může sama o sobě zdát neškodná, ale v kombinaci mohou vést k úspěšnému jailbreaku.
Jak zabránit útokům jailbreaku
Přestože útoky typu jailbreak představují vážnou hrozbu, existují kroky, které mohou organizace podniknout ke zmírnění rizik.
Implementujte robustní validaci vstupů
Jednou z nejúčinnějších obranných opatření je implementace robustního systému ověřování vstupů. To zahrnuje použití kombinace technik k analýze příchozích výzev a zjištění známek škodlivého úmyslu. Může to zahrnovat:
- Filtrování klíčových slov: Blokování výzev, které obsahují známá škodlivá klíčová slova nebo fráze.
- Analýza sentimentu: Identifikace podnětů, které mají negativní nebo nepřátelský tón.
- Analýza složitosti: Označování příliš složitých nebo komplikovaných výzev, protože by se mohlo jednat o pokusy o jejich znejasnění.
Průběžně monitorovat a aktualizovat modely
Situace v oblasti jailbreak útoků se neustále vyvíjí, proto je zásadní neustále sledovat nové techniky a podle toho aktualizovat modely. To zahrnuje pravidelné přetrénování modelů s využitím nových dat, která jim pomohou lépe identifikovat a odmítat škodlivé výzvy.
Je také důležité sledovat nejnovější výzkum v oblasti jailbreaků v LLM. Pochopením nejnovějších vektorů útoků můžete proaktivně posílit svou obranu.
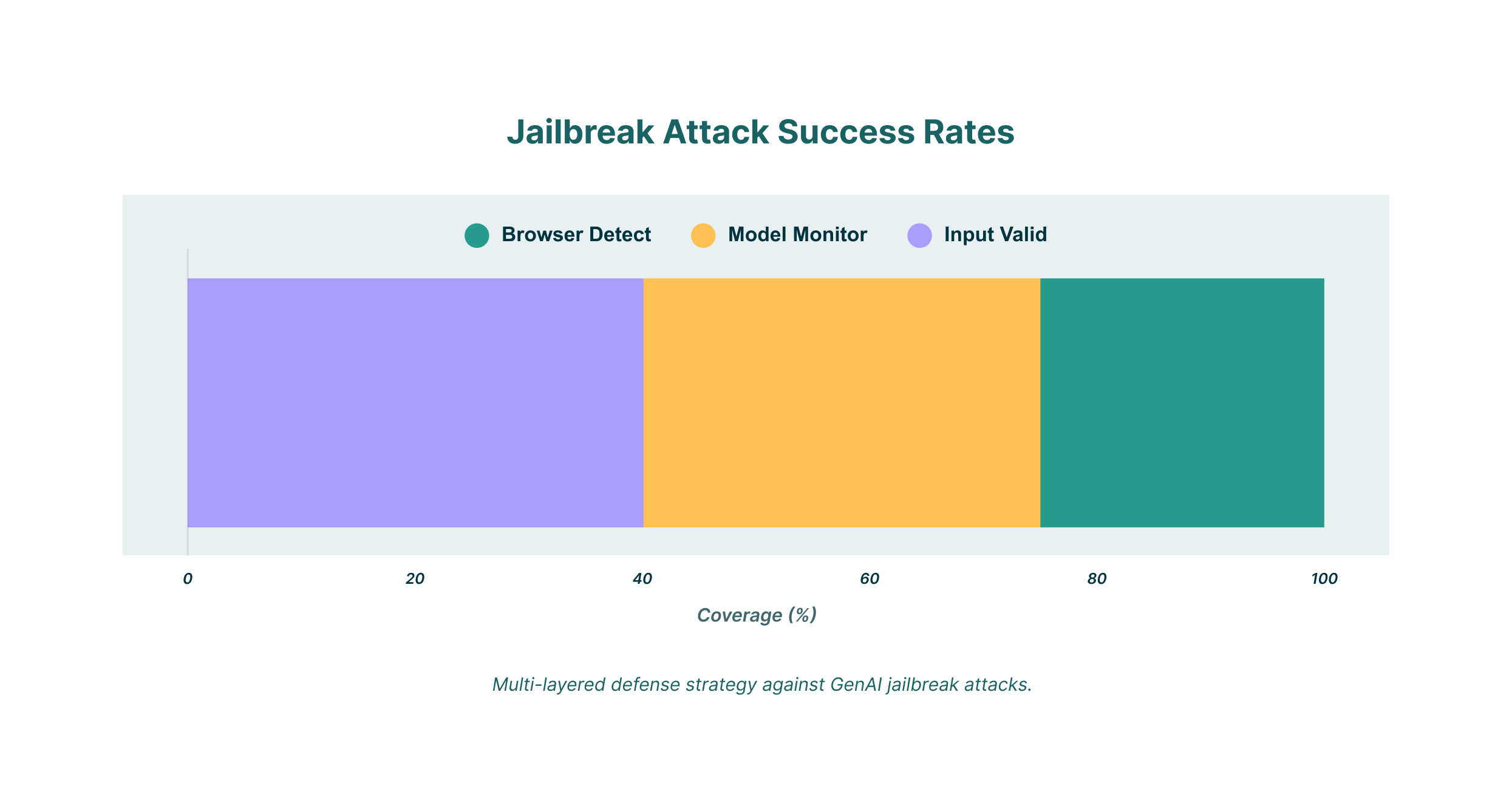 Využijte detekci a odezvu prohlížeče (BDR)
Využijte detekci a odezvu prohlížeče (BDR)
Pro organizace, které používají nástroje GenAI, může řešení Browser Detection and Response (BDR) poskytnout další vrstvu zabezpečení. Řešení BDR dokáže monitorovat veškerou aktivitu uživatelů v prohlížeči, včetně interakcí s modely GenAI. To umožňuje:
- Audit využití GenAI: Získejte kompletní přehled o tom, jak zaměstnanci v celé organizaci používají nástroje GenAI.
- Vynucení správy zabezpečení: Nastavte podrobné zásady pro omezení typů informací, které lze sdílet s LLM.
- Zabraňte úniku dat: Blokujte pokusy o sdílení citlivých firemních dat pomocí modelů GenAI.
LayerX poskytuje komplexní řešení BDR, které vám pomůže zabezpečit používání nástrojů GenAI. Analýzou veškeré aktivity prohlížeče dokáže LayerX detekovat a blokovat i ty nejsofistikovanější pokusy o jailbreak, čímž zajišťuje, že vaše organizace může využívat výhod GenAI, aniž by se vystavovala zbytečným rizikům.
Výzvy k jailbreaku pro konkrétní modely
I když jsou výše popsané techniky obecně použitelné pro většinu LLM, některé modely mají svá vlastní jedinečná zranitelnost.
Útěk z vězení s umělou inteligencí postavy
Jak již bylo zmíněno, umělá inteligence postav je obzvláště náchylná k zneužívání person. Pokud hledáte způsob, jak provést jailbreak umělé inteligence postav, zjistíte, že mnoho úspěšných pokusů zahrnuje vytvoření velmi specifické a detailní persony, kterou model přijme.
Útěk z vězení s AI Claude
Claude AI, vyvinutá společností Anthropic, je známá svými silnými bezpečnostními funkcemi. Není však imunní vůči útokům typu jailbreak. Úspěšný jailbreak Claude AI často zahrnuje použití kombinace obfuskace promptu a vícekrokového řetězení promptu k obejití jeho obrany.
Útěk z vězení s umělou inteligencí DeepSeek
DeepSeek AI je další výkonný LLM, na který se útočníci zaměřili. Jailbreak DeepSeek AI často vyžaduje techničtější přístup, jako je zneužití specifických zranitelností v architektuře modelu.
Řešení LayerX pro útoky typu jailbreak
Útoky typu jailbreak na GenAI představují vážnou hrozbu, která může mít pro organizace značné důsledky. Pochopením technik, které útočníci používají, a implementací vícevrstvé obranné strategie můžete svou organizaci před těmito nově vznikajícími hrozbami ochránit. To zahrnuje robustní validaci vstupů, průběžné monitorování vašich modelů a využití řešení BDR, jako je LayerX, k zabezpečení všech interakcí uživatelů s nástroji GenAI.
Svět jailbreaku s využitím umělé inteligence je neustálým bojem mezi inovacemi a bezpečností. Pokud budete informováni a budete proaktivní, můžete zajistit, že vaše organizace zůstane na správné straně tohoto boje.
