Генеративный ИИ (GenAI) открыл беспрецедентный потенциал производительности и инноваций, но также создал новые угрозы безопасности. Одной из наиболее серьёзных угроз является атака с джейлбрейком — метод обхода мер безопасности и этических норм, встроенных в большие языковые модели (LLM). В этой статье рассматриваются атаки с джейлбрейком на GenAI, используемые злоумышленниками методы и способы защиты организаций от этих новых угроз.
Что такое атаки с целью побега из тюрьмы?
Атака с джейлбрейком включает в себя создание специальных входных данных, известных как запросы на джейлбрейк, чтобы обманным путём заставить модель LLM генерировать ответы, нарушающие её собственные политики безопасности. Эти политики предназначены для предотвращения создания моделью вредоносного, неэтичного или вредоносного контента. Успешно выполнив джейлбрейк, злоумышленник может манипулировать ИИ для генерации дезинформации, разжигания ненависти или даже кода вредоносного ПО.
Проблема для организаций заключается в том, что эти атаки используют саму суть обработки языка LLM. Злоумышленники постоянно находят изощрённые способы формулировать запросы, чтобы обойти встроенные барьеры. Это создаёт непрерывную игру в кошки-мышки между разработчиками, пытающимися защитить свои модели, и злоумышленниками, ищущими новые уязвимости.
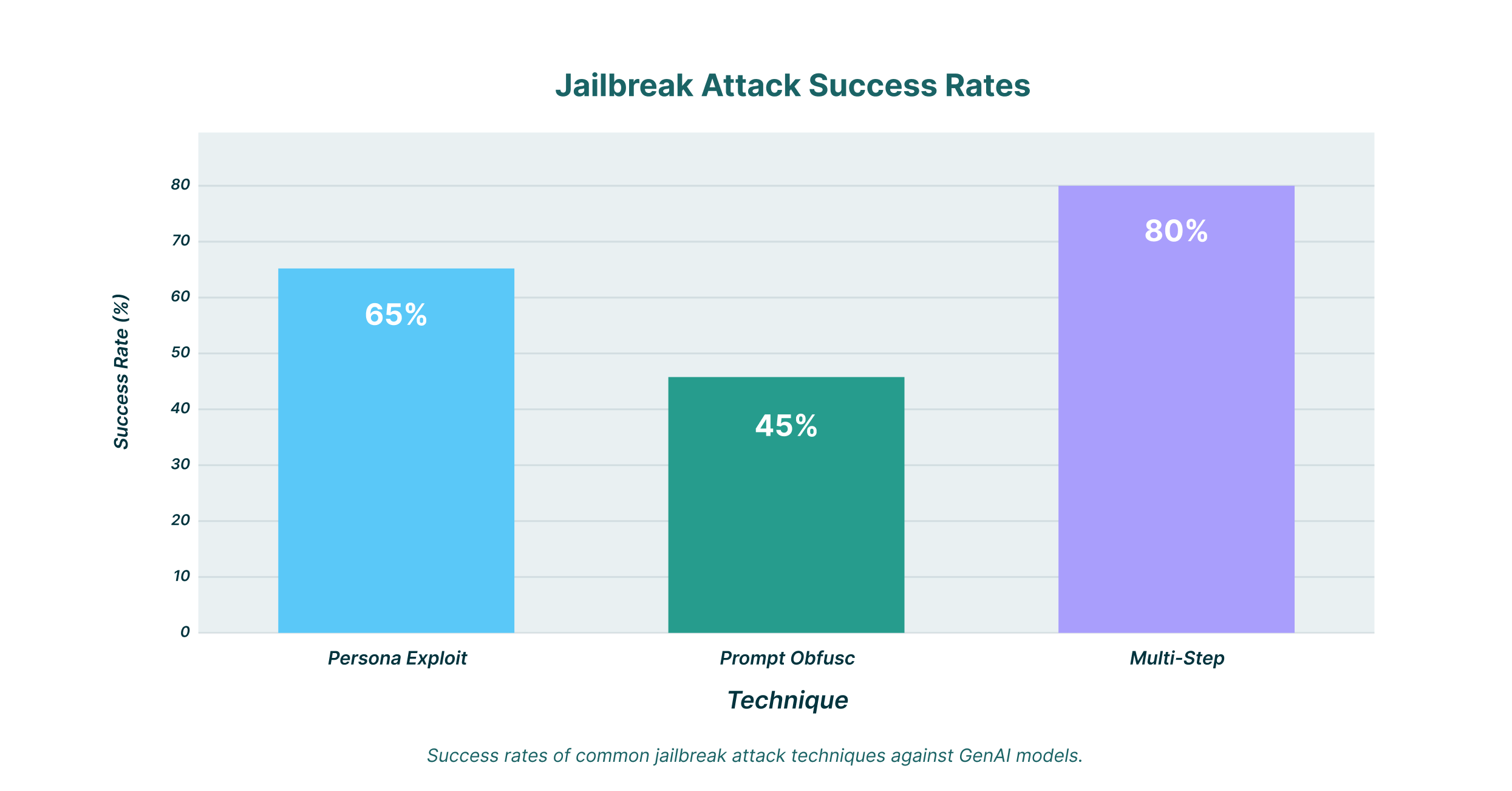 Распространенные методы джейлбрейка
Распространенные методы джейлбрейка
Злоумышленники разработали множество сложных методов взлома моделей ИИ. Понимание этих методов — первый шаг к созданию надёжной защиты.
Эксплуатация персоны
Одним из наиболее распространённых методов является эксплуатация персоны. В этом случае злоумышленник просит модель LLM принять определённую персону, не связанную обычными этическими ограничениями. Например, пользователь может попросить модель ответить от лица вымышленного персонажа из фильма, известного своим аморальным поведением. Формулируя запрос в рамках этого вымышленного контекста, злоумышленник часто может заставить модель сгенерировать контент, который она в противном случае бы отвергла.
Это особенно эффективный метод для джейлбрейка ИИ-персонажей. Эти модели разработаны для общения и вовлечения в процесс, что делает их более уязвимыми для подобных манипуляций. Тщательно продуманная подсказка для джейлбрейка ИИ-персонажей может привести к созданию нежелательного или вредоносного контента.
Быстрое запутывание
Другой популярный метод — обфускация подсказок. Это подразумевает маскировку вредоносного запроса в, казалось бы, безобидном подсказке. Например, злоумышленник может внедрить вредоносную инструкцию в длинную и сложную задачу программирования или в творческий текст. Цель — сбить с толку фильтры безопасности модели, которые могут не обнаружить скрытое злонамеренное намерение.
Этот метод часто используется для выполнения запроса на джейлбрейк ИИ. Затрудняя анализ запроса, злоумышленники могут обойти начальный уровень безопасности и заставить модель сосредоточиться на замаскированной инструкции.
Многошаговая цепочка подсказок
Более сложные атаки часто включают в себя серию подсказок, которые выстраиваются одна за другой. Это называется многошаговой цепочкой подсказок. Злоумышленник начинает с серии безобидных вопросов, чтобы установить контакт с моделью, и постепенно добавляет более манипулятивный язык. К моменту отправки вредоносного запроса модель уже «подготовлена» к большей послушности.
Этот метод особенно опасен, поскольку его трудно обнаружить. Каждая подсказка сама по себе может показаться безобидной, но в совокупности они могут привести к успешному джейлбрейку.
Как предотвратить атаки с джейлбрейком
Хотя атаки с целью побега из тюрьмы представляют серьезную угрозу, организации могут предпринять некоторые шаги для снижения рисков.
Реализуйте надежную проверку входных данных
Одним из наиболее эффективных способов защиты является внедрение надежной системы проверки входных данных. Это предполагает использование комбинации методов анализа входящих запросов на наличие признаков злонамеренного намерения. Это может включать:
- Фильтрация ключевых слов: блокировка запросов, содержащих известные вредоносные ключевые слова или фразы.
- Анализ настроений: выявление подсказок, имеющих негативный или враждебный тон.
- Анализ сложности: отметка слишком сложных или запутанных подсказок, поскольку они могут быть попытками запутать читателя.
Постоянный мониторинг и обновление моделей
Ландшафт атак с целью джейлбрейка постоянно меняется, поэтому крайне важно постоянно отслеживать новые методы и соответствующим образом обновлять свои модели. Это включает в себя регулярное переобучение моделей с использованием новых данных, чтобы они могли лучше распознавать и блокировать вредоносные запросы.
Также важно быть в курсе последних исследований в области запросов на джейлбрейк для LLM. Понимая актуальные векторы атак, вы сможете заблаговременно укрепить свою защиту.
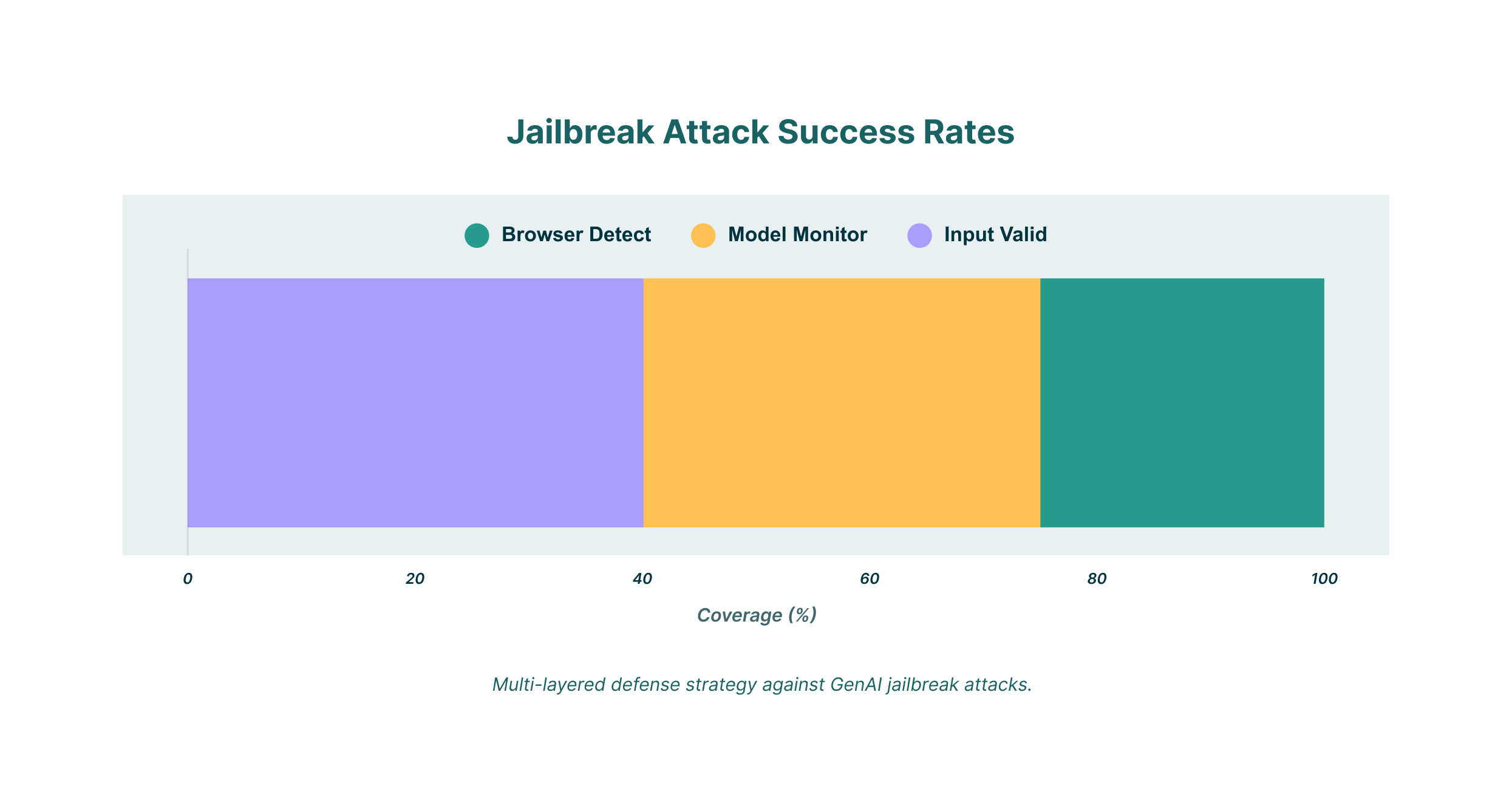 Использовать обнаружение и реагирование браузера (BDR)
Использовать обнаружение и реагирование браузера (BDR)
Для организаций, использующих инструменты GenAI, решение Browser Detection and Response (BDR) может обеспечить дополнительный уровень безопасности. Решение BDR может отслеживать всю активность пользователя в браузере, включая взаимодействие с моделями GenAI. Это позволяет:
- Аудит использования GenAI: получите полную картину того, как сотрудники используют инструменты GenAI по всей организации.
- Обеспечьте управление безопасностью: установите детальные политики для ограничения типов информации, которой можно делиться с LLM.
- Предотвратите утечку данных: блокируйте попытки поделиться конфиденциальными корпоративными данными с моделями GenAI.
LayerX предлагает комплексное решение BDR, которое поможет вам обезопасить использование инструментов GenAI. Анализируя всю активность браузера, LayerX может обнаруживать и блокировать даже самые изощрённые попытки взлома, гарантируя, что ваша организация сможет воспользоваться преимуществами GenAI, не подвергая себя ненужным рискам.
Запросы на джейлбрейк для определенных моделей
Хотя описанные выше методы в целом применимы к большинству LLM, некоторые модели имеют свои собственные уникальные уязвимости.
Побег из тюрьмы с искусственным интеллектом персонажа
Как упоминалось ранее, ИИ-персонажи особенно подвержены эксплуатации персонажей. Если вы ищете способ взломать ИИ-персонажей, вы обнаружите, что многие успешные попытки подразумевают создание очень специфичной и подробной персоны, которую затем использует модель.
Клод ИИ побег из тюрьмы
Claude AI, разработанный компанией Anthropic, известен своими мощными функциями безопасности. Однако он не застрахован от атак с целью джейлбрейка. Успешный джейлбрейк Claude AI часто подразумевает использование комбинации обфускации подсказок и многошаговой цепочки подсказок для обхода защиты.
DeepSeek AI Jailbreak
DeepSeek AI — ещё одна мощная модель управления правами (LLM), подвергшаяся атакам злоумышленников. Для взлома DeepSeek AI часто требуется более технический подход, например, эксплуатация конкретных уязвимостей в архитектуре модели.
Решение LayerX против атак с джейлбрейком
Атаки с джейлбрейком на GenAI представляют собой серьёзную угрозу, которая может иметь серьёзные последствия для организаций. Понимая методы, используемые злоумышленниками, и реализуя многоуровневую стратегию защиты, вы сможете защитить свою организацию от этих новых угроз. Это включает в себя надёжную проверку входных данных, непрерывный мониторинг моделей и использование решения BDR, такого как LayerX, для защиты всех взаимодействий пользователей с инструментами GenAI.
Мир джейлбрейка ИИ — это постоянная борьба между инновациями и безопасностью. Оставаясь в курсе событий и действуя на опережение, вы можете гарантировать, что ваша организация будет на правильной стороне в этой борьбе.
