Szybka integracja generatywnej sztucznej inteligencji (GenAI) z procesami pracy w przedsiębiorstwach obiecuje znaczny wzrost produktywności. Od generowania kodu po analizę rynku, modele dużych języków (LLM) stają się niezbędnymi współpilotami. Jednak to rosnące poleganie na nich niesie ze sobą subtelne, ale poważne ryzyko: halucynacje sztucznej inteligencji. Nie są to zwykłe błędy ani proste pomyłki; stanowią one przypadki, w których model sztucznej inteligencji generuje przekonujące, ale całkowicie fałszywe, bezsensowne lub oderwane od rzeczywistości informacje. Dla analityków bezpieczeństwa, dyrektorów ds. bezpieczeństwa informacji (CISO) i liderów IT zrozumienie mechanizmów i konsekwencji tych manipulacji to pierwszy krok w kierunku ograniczenia nowego i złożonego wektora zagrożeń.
W miarę jak organizacje zachęcają do korzystania z GenAI, aby utrzymać konkurencyjność, nieświadomie otwierają drzwi scenariuszom, w których wadliwe wyniki AI mogą prowadzić do katastrofalnych decyzji biznesowych, naruszeń bezpieczeństwa danych i nieprzestrzegania przepisów. Problem polega na tym, że błędy GenAI często wydają się prawdopodobne, co utrudnia ich wykrycie przeciętnemu użytkownikowi. Pracownik może poprosić LLM o streszczenie nowego przepisu dotyczącego zgodności, a następnie otrzymać pewną odpowiedź, która pomija kluczową klauzulę lub wymyśla nieistniejącą. Wzrost produktywności jest natychmiast niwelowany przez koszty napraw. Dlaczego tak się dzieje i co można zrobić, aby chronić przedsiębiorstwo? Odpowiedź leży w zrozumieniu natury samych modeli i wdrożeniu solidnego nadzoru. 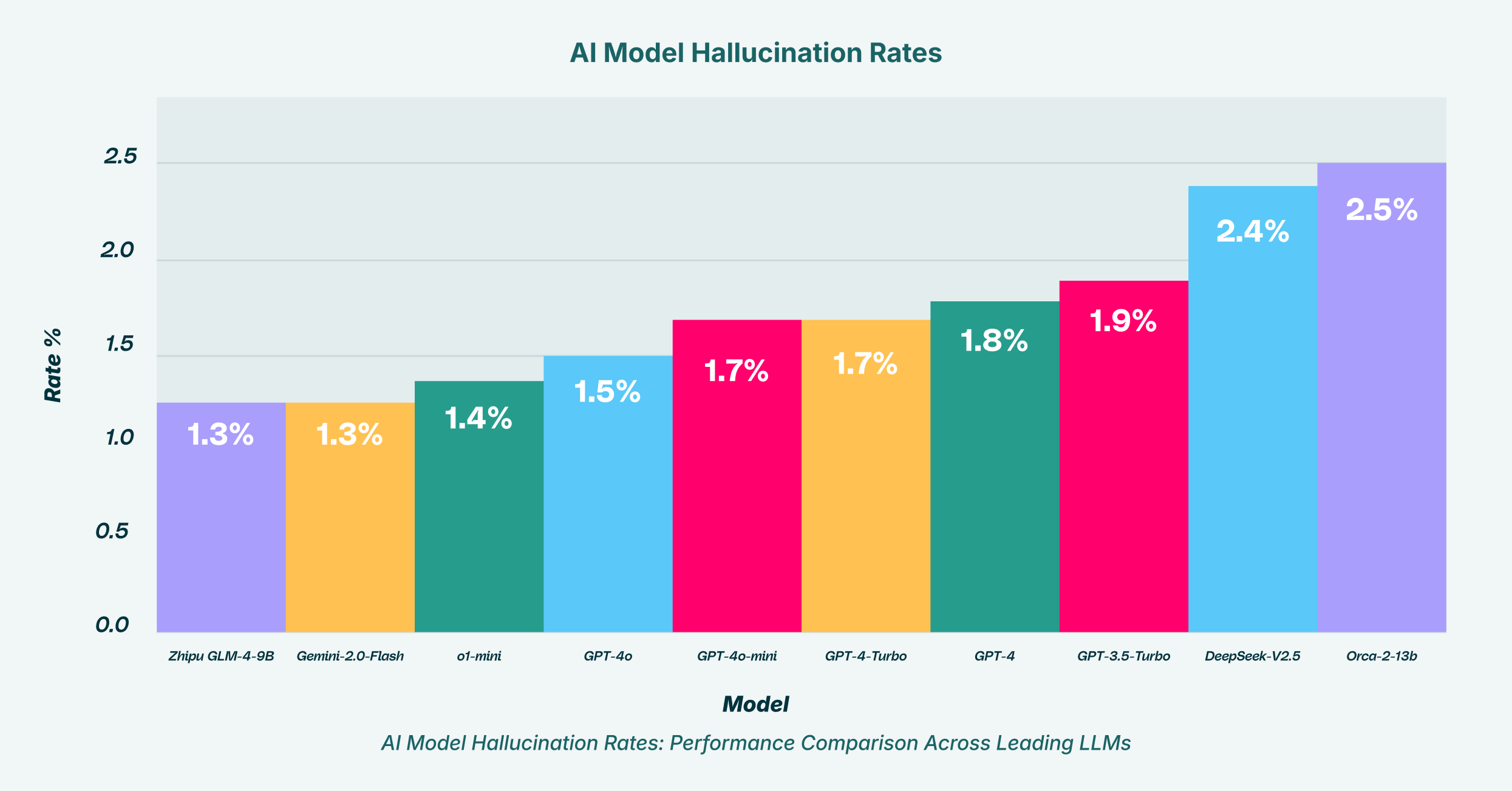
Dekonstrukcja halucynacji AI
W swojej istocie halucynacja sztucznej inteligencji występuje, gdy model generuje dane wyjściowe, które nie są uzasadnione danymi szkoleniowymi ani dostarczonymi danymi wejściowymi. Modele LLM to systemy probabilistyczne; ich celem jest przewidywanie kolejnego najbardziej prawdopodobnego słowa w sekwencji, a nie rozróżnianie prawdy od fałszu. Ten proces, choć potężny, może prowadzić do wymyślania faktów, tworzenia cytatów z nieistniejących źródeł lub generowania kodu z subtelnymi, ale krytycznymi lukami bezpieczeństwa. Nie są to przypadkowe błędy, lecz nieodłączna część działania modeli obecnej generacji.
Problem ten nabiera jeszcze większego znaczenia, gdy omawiamy halucynacje LLM, które są specyficzne dla modeli językowych. Modele te uczą się wzorców, gramatyki i stylu z ogromnych zbiorów danych zebranych z internetu. Jeśli dane treningowe zawierają błędy, nieścisłości lub sprzeczne informacje, model nauczy się ich i odtworzy. Może on z przekonaniem stwierdzić nieprawdziwy fakt historyczny lub połączyć szczegóły z dwóch odrębnych wydarzeń w jedną, fikcyjną narrację. Wyobraźmy sobie analityka marketingowego korzystającego z narzędzia GenAI do badania konkurencji. Narzędzie to może wygenerować raport szczegółowo opisujący premierę nowego produktu konkurencji, wraz z wymyślonymi funkcjami i fikcyjną datą premiery, co skłoni analityka do opracowania kontrstrategii opartej na całkowicie fałszywych przesłankach.
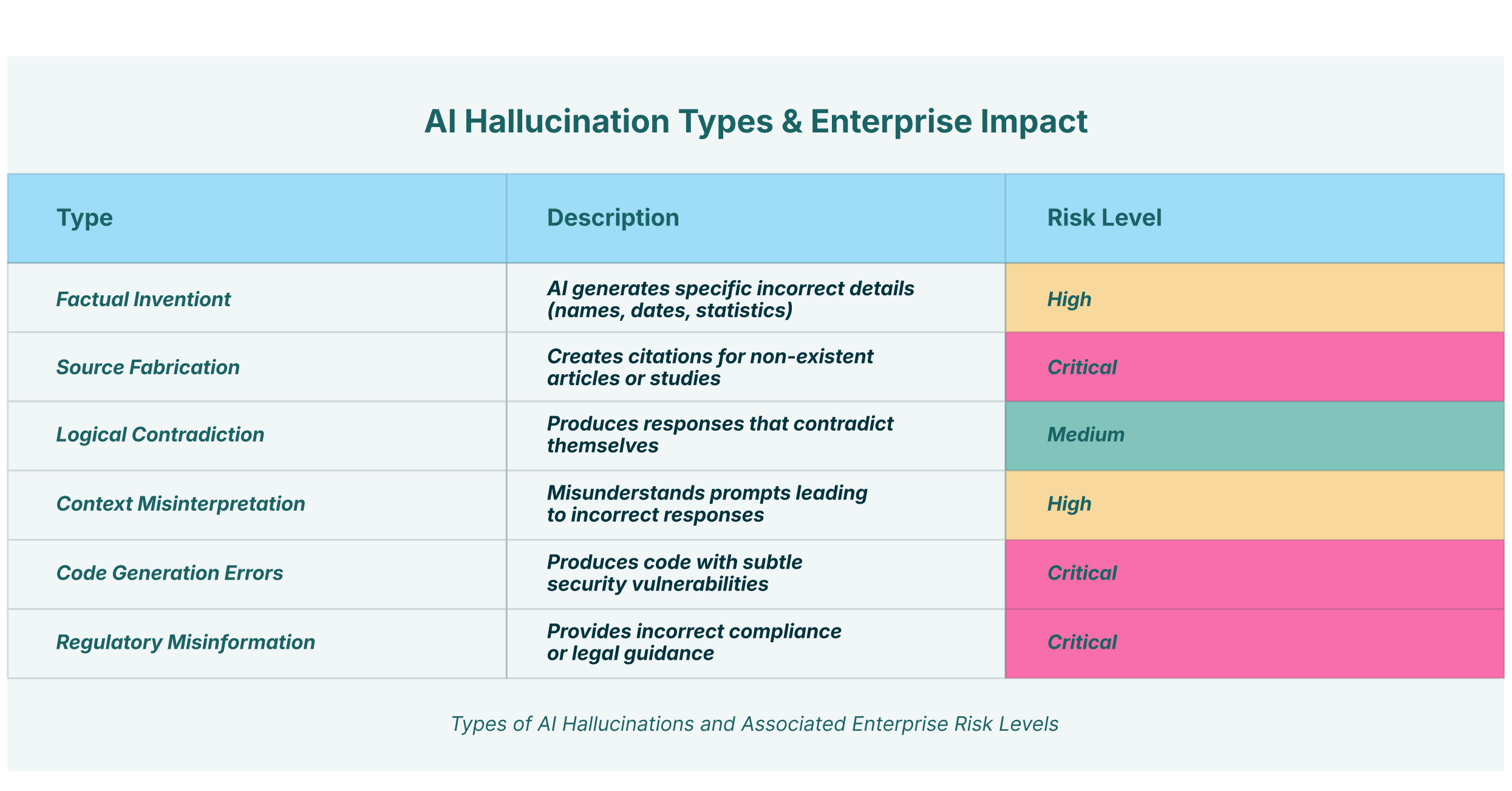
Te halucynacje modelowe nie stanowią pojedynczego, monolitycznego problemu. Objawiają się w różnych formach:
- Faktyczne zmyślenie: Model generuje określone, nieprawdziwe szczegóły, takie jak imiona, daty i statystyki.
- Fabrykowanie źródeł: Sztuczna inteligencja tworzy cytaty z artykułów, badań i spraw sądowych, które nie istnieją, nadając swoim twierdzeniom pozory autorytetu.
- Sprzeczność logiczna: Model generuje odpowiedź, która jest sprzeczna sama ze sobą lub narusza podstawowe zasady logiczne.
Sednem problemu jest to, że tym modelom brakuje prawdziwego mechanizmu wnioskowania. Są mistrzami naśladownictwa, a nie rozumienia. Dla przedsiębiorstwa oznacza to, że każdy wynik narzędzia GenAI musi być traktowany z podejrzliwością, dopóki nie zostanie zweryfikowany.
Techniczne korzenie halucynacji modelowych
Aby skutecznie przeciwdziałać zagrożeniom związanym ze sztuczną inteligencją, konieczne jest zrozumienie, dlaczego halucynacje modeli występują na poziomie technicznym. Nie są to jedynie przypadkowe dziwactwa, ale wynikają z fundamentalnej architektury i metodologii szkolenia LLM. Pod wieloma względami są one cechą probabilistycznej natury tych systemów, a nie tylko błędem, który należy naprawić. Modele są projektowane tak, aby generować spójne i poprawne gramatycznie sekwencje tekstu, ale brakuje im wewnętrznego modułu weryfikacji faktów ani połączenia z weryfikowaną bazą wiedzy w czasie rzeczywistym.
Na częstość występowania błędów GenAI wpływa kilka kluczowych czynników:
- Generowanie probabilistyczne: LLM nie „wie” rzeczy w ludzkim rozumieniu tego słowa. Po otrzymaniu polecenia oblicza prawdopodobieństwo kolejnego słowa, biorąc pod uwagę poprzednie. Halucynacja może wystąpić, jeśli model podąża ścieżką statystycznie prawdopodobną, ale nieprawdziwą. Zasadniczo polega on na ułożeniu zdania brzmiącego najbardziej prawdopodobnie, a nie najprawdziwszego.
- Ograniczenia danych treningowych: Modele są tak dobre, jak dane, na których są trenowane. Jeśli zbiór danych treningowych jest nieaktualny, zawiera wrodzone błędy lub brakuje informacji na temat niszowego tematu, model jest bardziej skłonny do „uzupełniania luk” sfabrykowanymi szczegółami. Może on posiadać rozległą wiedzę aż do daty granicznej treningu, ale będzie generował halucynacje dotyczące zdarzeń, które miały miejsce później.
- Błędy kodowania i dekodowania: Podczas procesu przekształcania złożonych idei w reprezentacje matematyczne (wektory) i z powrotem w tekst zrozumiały dla człowieka, niuanse mogą zostać utracone. Może to prowadzić do błędnej interpretacji komunikatu przez model lub wygenerowania odpowiedzi, która jest semantycznie podobna, ale kontekstowo błędna.
- Nadmierne dopasowanie: W niektórych przypadkach model może być „przeoptymalizowany” w oparciu o dane treningowe, co powoduje zapamiętywanie określonych fraz lub wzorców. Po podaniu czegoś podobnego, ale nie identycznego, może powrócić do zapamiętanej, ale nieadekwatnej odpowiedzi, tworząc halucynacje.
Te techniczne podstawy dowodzą, że halucynacje LLM stanowią problem systemowy. Samo proszenie pracowników o „zachowanie ostrożności” to niewystarczająca strategia. Bez warstwy kontroli technicznej organizacja pozostaje narażona na konsekwencje tych wrodzonych wad modelu. Jest to szczególnie istotne, ponieważ pracownicy coraz częściej korzystają z narzędzi GenAI opartych na przeglądarce i aplikacji SaaS do codziennych zadań, często wykraczających poza zakres tradycyjnego bezpieczeństwa IT.
Konsekwencje błędów GenAI w świecie rzeczywistym
Teoretyczne ryzyko związane z halucynacjami AI przekłada się na namacalne, poważne konsekwencje dla współczesnych przedsiębiorstw. Błędy te nie ograniczają się do błahych niedokładności; mogą one powodować incydenty bezpieczeństwa, naruszać integralność danych i prowadzić do poważnych zobowiązań w zakresie zgodności. Przeglądarka, jako główny interfejs dla większości aplikacji GenAI i SaaS, stała się krytycznym polem bitwy, na którym te zagrożenia się ujawniają.
Wyobraź sobie scenariusz w instytucji finansowej. Młodszy analityk korzysta z zewnętrznego, niesprawdzonego rozszerzenia GenAI w swojej przeglądarce, będącego formą „shadow SaaS”, aby przyspieszyć due diligence potencjalnej inwestycji. Wkleja poufne, niepubliczne dane finansowe do interfejsu czatu. Model, w odpowiedzi, cierpi na jedną z klasycznych halucynacji modelowych: generuje podsumowanie, które błędnie przedstawia zobowiązania firmy docelowej, przedstawiając lepszą kondycję finansową niż w rzeczywistości. Działając na podstawie tych wadliwych danych, firma podejmuje błędną decyzję inwestycyjną, co prowadzi do bezpośrednich strat finansowych. Problem jest dwojaki: popełniono błąd strategiczny oparty na błędzie GenAI, a poufne dane korporacyjne zostały wykradzione do niezaufanego zewnętrznego LLM, co doprowadziło do poważnego wycieku danych.
W tym miejscu rozwiązanie LayerX do bezpieczeństwa GenAI staje się niezbędne. Zapewniając pełny audyt wszystkich aplikacji SaaS, w tym nieautoryzowanego shadow IT, LayerX pozwala organizacjom identyfikować, kiedy i gdzie pracownicy korzystają z tych narzędzi. Następnie można wdrożyć szczegółowe zabezpieczenia oparte na analizie ryzyka. Na przykład, można wdrożyć politykę blokującą wklejanie poufnych danych osobowych lub finansowych do chatbotów GenAI, zapobiegając w ten sposób wyciekowi danych.
Rozważmy inny przypadek, tym razem w organizacji opieki zdrowotnej. Lekarz, poszukując informacji na temat rzadkiej interakcji lekowej, zwraca się do medycznego chatbota opartego na sztucznej inteligencji. Sztuczna inteligencja, podatna na halucynacje LLM, pewnie tworzy odpowiedź, twierdząc, że nie ma znanych interakcji. Lekarz, pod presją czasu, akceptuje odpowiedź. Potencjalne ryzyko dla pacjenta jest ogromne. Łatwość obsługi aplikacji SaaS sprawia, że jest to ryzyko o wysokiej częstotliwości. Zdolność LayerX do kontrolowania aktywności użytkowników w tych aplikacjach ma kluczowe znaczenie. System może śledzić i zarządzać interakcjami z usługami udostępniania plików i dyskami online, zapobiegając przypadkowemu lub złośliwemu wyciekowi poufnych informacji, w tym błędnych raportów generowanych przez sztuczną inteligencję, które mogłyby w przeciwnym razie rozprzestrzenić się po całej organizacji.
Te hipotetyczne scenariusze podkreślają pewien schemat:
- Użytkownicy wdrażają nowe narzędzia GenAI w celu zwiększenia produktywności, często bez oficjalnego zezwolenia, tworząc ekosystem „shadow SaaS”.
- Narzędzia te są podatne na halucynacje sztucznej inteligencji, co skutkuje generowaniem przekonujących, lecz niebezpiecznie nieprawdziwych wyników.
- Interakcja ta, odbywająca się w przeglądarce, omija wiele tradycyjnych zabezpieczeń sieciowych, co prowadzi do wycieku danych i podejmowania złych decyzji.
Bez rozwiązania zapewniającego widoczność i kontrolę bezpośrednio na poziomie przeglądarki, przedsiębiorstwa działają po omacku. Brakuje im narzędzi do odpowiedniego zabezpieczenia użytkowania SaaS, co naraża je na podwójne zagrożenia: shadow IT i zawodną sztuczną inteligencję.
Krytyczna potrzeba warstw walidacji AI
Biorąc pod uwagę, że halucynacje modeli są nieodłączną częścią obecnej technologii GenAI, organizacje nie mogą po prostu czekać, aż twórcy modeli rozwiążą problem. Odpowiedzialność za wdrożenie zabezpieczeń spoczywa na przedsiębiorstwie. W tym miejscu koncepcja warstw walidacji AI staje się strategicznym imperatywem. Warstwa walidacji to system lub proces, który znajduje się pomiędzy użytkownikiem a modelem AI i służy do weryfikacji, oczyszczania lub blokowania treści generowanych przez AI, zanim będzie można na nie zareagować lub wyrządzić im szkodę.
Warstwa walidacji AI nie polega na jej zastępowaniu, lecz na jej zabezpieczeniu. Działa jak kognitywny pas bezpieczeństwa, chroniąc użytkownika i organizację przed konsekwencjami nieoczekiwanych błędów GenAI. Warstwy te mogą przybierać różne formy, od prostych filtrów opartych na słowach kluczowych po bardziej złożone systemy, które porównują dane wyjściowe AI z zaufanymi wewnętrznymi bazami wiedzy. Jednak w większości przypadków użycia w przedsiębiorstwach najskuteczniejsza warstwa walidacji to taka, która działa tam, gdzie ryzyko jest największe: w przeglądarce użytkownika.
LayerX działa jako potężna i praktyczna warstwa walidacji AI poprzez rozszerzenie przeglądarki korporacyjnej. Zapewnia zarządzanie bezpieczeństwem, którego brakuje w modelu SaaS bezpośrednio do użytkownika. Zamiast polegać na obietnicach dostawcy AI lub staranności użytkownika, LayerX egzekwuje zasady w momencie interakcji.
- Mapowanie wykorzystania GenAI: LayerX umożliwia organizacji wykrywanie i mapowanie wszystkich używanych narzędzi GenAI, w tym shadow SaaS. Ta widoczność stanowi podstawę każdej strategii bezpieczeństwa. Nie da się zabezpieczyć czegoś, czego nie widać.
- Egzekwowanie zasad bezpieczeństwa: Po zmapowaniu użycia, CISO mogą egzekwować szczegółowe kontrole. Można skonfigurować zasady ograniczające typy danych udostępnianych systemom LLM, zapobiegając w ten sposób przekazywaniu poufnych informacji firmowych do modeli zewnętrznych, gdzie mogłyby one zostać ujawnione lub wykorzystane do szkolenia. Na przykład, można utworzyć regułę blokującą lub blokującą wszelkie treści zidentyfikowane jako dane osobowe, zanim opuszczą one przeglądarkę.
- Ograniczanie niebezpiecznych działań: Rozwiązanie może monitorować ryzykowne zachowania, takie jak pobieranie i wykonywanie kodu wygenerowanego przez sztuczną inteligencję, który może zawierać luki w zabezpieczeniach wynikające z halucynacji LLM. Może również zapobiegać przesyłaniu poufnych dokumentów do nieautoryzowanych aplikacji do udostępniania plików, blokując kluczowy kanał wycieku danych.
Koncentrując się na przeglądarce, LayerX skutecznie tworzy granicę bezpieczeństwa wokół najbardziej nieprzewidywalnego elementu nowoczesnego stosu korporacyjnego: interakcji między użytkownikiem a sztuczną inteligencją innej firmy. Akceptuje fakt, że halucynacje AI będą się pojawiać i zapewnia niezbędne mechanizmy kontroli, aby zarządzać tym ryzykiem. Przekształca przeglądarkę ze słabego ogniwa w wąskie gardło dla egzekwowania bezpieczeństwa, zapewniając, że korzyści z produktywności GenAI mogą być realizowane bez narażania organizacji na niedopuszczalne zagrożenia. Dla każdej branży, a szczególnie dla regulowanych, takich jak finanse i opieka zdrowotna, taka warstwa walidacji nie jest już luksusem, lecz kluczowym elementem nowoczesnej architektury bezpieczeństwa.
