Sztuczna inteligencja generatywna (GenAI) umożliwiła bezprecedensowy wzrost produktywności i innowacyjności, ale jednocześnie wprowadziła nowe możliwości w zakresie zagrożeń bezpieczeństwa. Jednym z najpoważniejszych zagrożeń jest atak typu jailbreak, technika wykorzystywana do omijania mechanizmów kontroli bezpieczeństwa i etyki wbudowanych w duże modele językowe (LLM). W niniejszym artykule omówiono ataki typu jailbreak na GenAI, metody stosowane przez atakujących oraz sposoby, w jakie organizacje mogą chronić się przed tymi nowymi zagrożeniami.
Czym są ataki jailbreak?
Atak typu jailbreak polega na tworzeniu specjalnych danych wejściowych, zwanych monitami jailbreak, w celu nakłonienia LLM do generowania odpowiedzi naruszających jego własne zasady bezpieczeństwa. Zasady te mają na celu uniemożliwienie modelowi generowania szkodliwych, nieetycznych lub złośliwych treści. Po pomyślnym wykonaniu jailbreaku atakujący może manipulować sztuczną inteligencją, aby generowała dezinformację, mowę nienawiści, a nawet kod złośliwego oprogramowania.
Wyzwaniem dla organizacji jest to, że ataki te wykorzystują samą naturę przetwarzania języka przez LLM. Atakujący nieustannie szukają kreatywnych sposobów na formułowanie swoich żądań, aby ominąć wbudowane zabezpieczenia. To tworzy ciągłą grę w kotka i myszkę między programistami próbującymi zabezpieczyć swoje modele a złośliwymi podmiotami poszukującymi nowych luk w zabezpieczeniach.
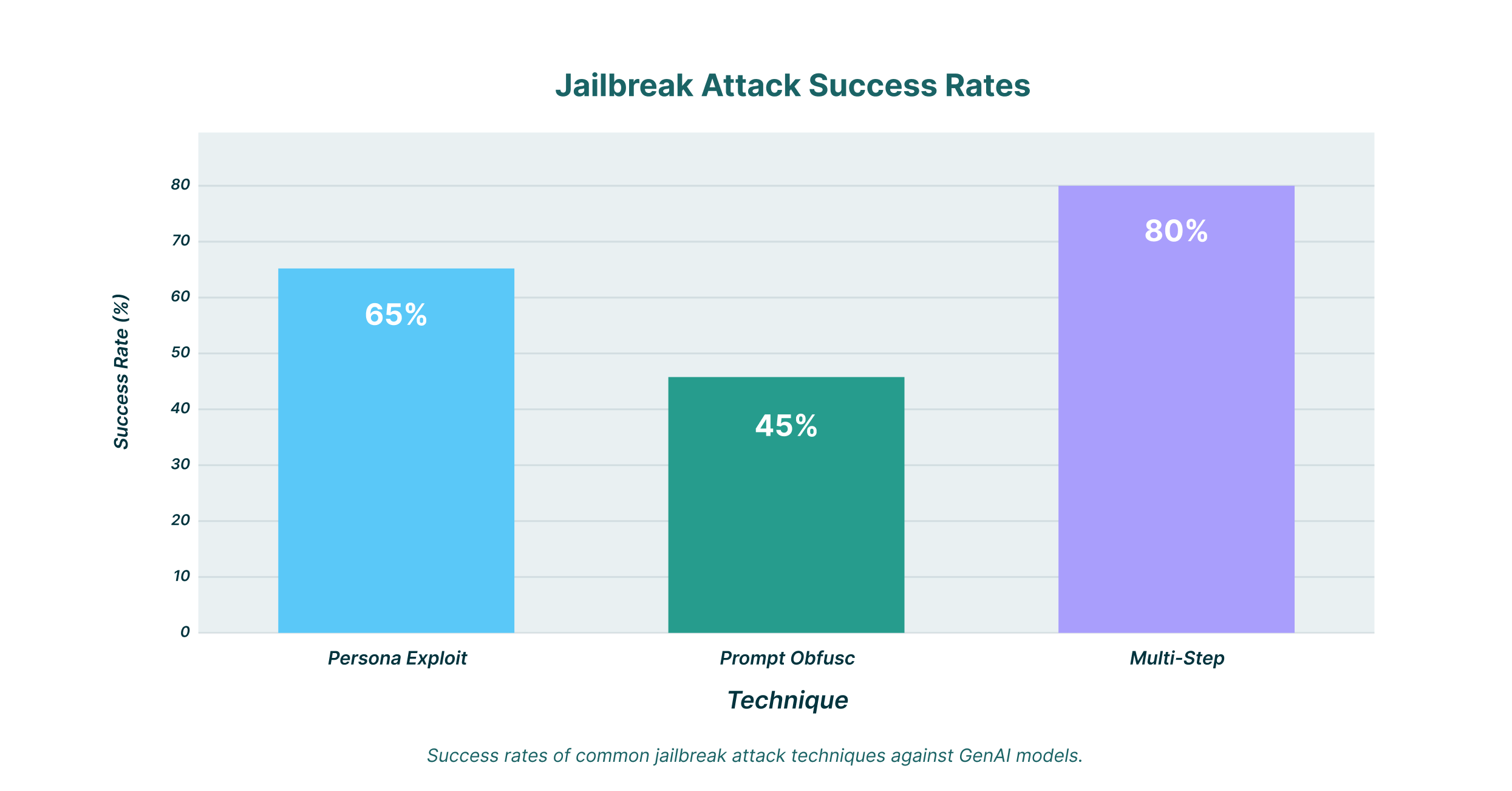
Atakujący opracowali szereg zaawansowanych technik jailbreakingu modeli sztucznej inteligencji. Zrozumienie tych metod to pierwszy krok do zbudowania solidnej obrony.
Wykorzystywanie persony
Jedną z najczęstszych metod jest eksploatacja persony. W tym scenariuszu atakujący nakazuje modelowi LLM przyjęcie określonej persony, która nie podlega typowym ograniczeniom etycznym. Na przykład, użytkownik może poprosić model o odpowiedź jako fikcyjna postać z filmu, znana z niemoralnego zachowania. Umieszczając prośbę w tym fikcyjnym kontekście, atakujący często może nakłonić model do wygenerowania treści, które w innym przypadku odrzuciłby.
To szczególnie skuteczna technika jailbreaku sztucznej inteligencji postaci. Modele te są zaprojektowane tak, aby były konwersacyjne i angażujące, co może je uczynić bardziej podatnymi na tego typu manipulacje. Starannie skonstruowany komunikat jailbreaku sztucznej inteligencji postaci może prowadzić do generowania nieodpowiednich lub szkodliwych treści.
Szybkie zaciemnianie
Inną popularną techniką jest zaciemnianie komunikatów. Polega ono na ukryciu złośliwego żądania w pozornie nieszkodliwym komunikacie. Na przykład, atakujący może osadzić szkodliwą instrukcję w długim i złożonym problemie programistycznym lub w tekście kreatywnym. Celem jest zmylenie filtrów bezpieczeństwa modelu, które mogą nie być w stanie wykryć złośliwego zamiaru ukrytego w szumie.
Ta metoda jest często używana do wykonania polecenia jailbreaku AI. Utrudniając analizę polecenia, atakujący mogą ominąć początkową warstwę zabezpieczeń i sprawić, że model skupi się na zamaskowanej instrukcji.
Łańcuchowanie wieloetapowe
Bardziej zaawansowane ataki często obejmują serię nachodzących na siebie komunikatów. Jest to znane jako wieloetapowe łączenie komunikatów. Atakujący zaczyna od serii niewinnych pytań, aby nawiązać kontakt z modelem, i stopniowo wprowadza bardziej manipulacyjny język. Zanim złośliwe żądanie zostanie wysłane, model jest już „przygotowany” do większej podatności.
Ta technika jest szczególnie niebezpieczna, ponieważ może być trudna do wykrycia. Każdy komunikat sam w sobie może wydawać się nieszkodliwy, ale w połączeniu mogą doprowadzić do udanego jailbreaku.
Jak zapobiegać atakom typu jailbreak
Ataki typu jailbreak stanowią poważne zagrożenie, jednak organizacje mogą podjąć pewne kroki w celu ograniczenia ryzyka.
Wdrożenie solidnej walidacji danych wejściowych
Jedną z najskuteczniejszych metod obrony jest wdrożenie solidnego systemu walidacji danych wejściowych. Polega on na wykorzystaniu kombinacji technik do analizy przychodzących monitów pod kątem oznak złośliwych zamiarów. Może to obejmować:
- Filtrowanie słów kluczowych: blokowanie monitów zawierających znane złośliwe słowa kluczowe lub frazy.
- Analiza sentymentu: identyfikacja podpowiedzi o wydźwięku negatywnym lub wrogim.
- Analiza złożoności: oznaczanie komunikatów, które są zbyt skomplikowane lub zawiłe, ponieważ mogą być próbą zaciemnienia.
Ciągłe monitorowanie i aktualizowanie modeli
Krajobraz ataków typu jailbreak stale ewoluuje, dlatego kluczowe jest ciągłe monitorowanie nowych technik i odpowiednie aktualizowanie modeli. Obejmuje to regularne przeszkolenie modeli z wykorzystaniem nowych danych, aby pomóc im lepiej identyfikować i odrzucać złośliwe komunikaty.
Ważne jest również, aby być na bieżąco z najnowszymi badaniami dotyczącymi jailbreaku LLM. Rozumiejąc najnowsze wektory ataków, możesz proaktywnie wzmocnić swoją obronę.
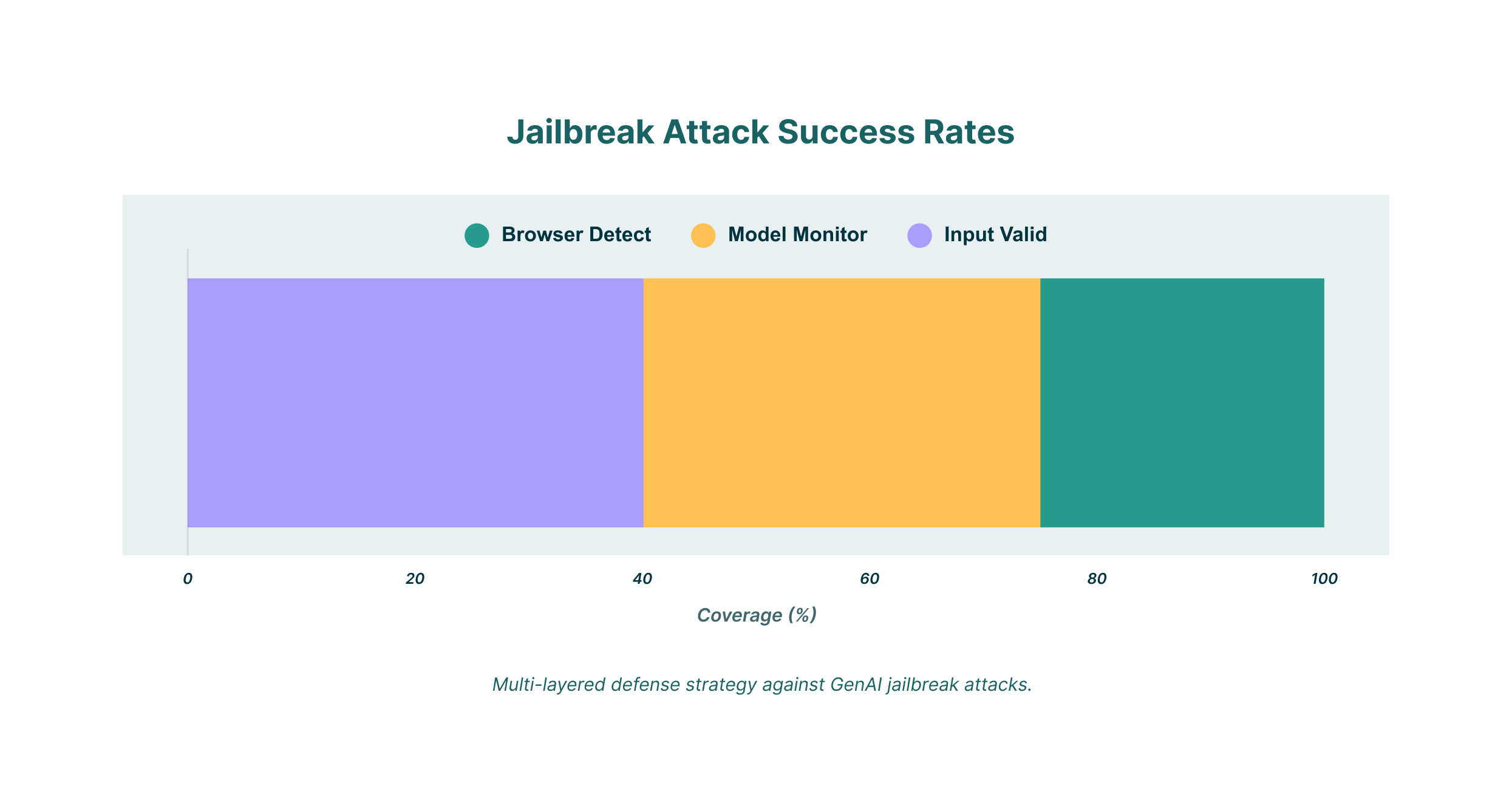 Wykorzystaj wykrywanie i reagowanie przeglądarki (BDR)
Wykorzystaj wykrywanie i reagowanie przeglądarki (BDR)
Dla organizacji korzystających z narzędzi GenAI, rozwiązanie Browser Detection and Response (BDR) może zapewnić dodatkową warstwę bezpieczeństwa. Rozwiązanie BDR może monitorować całą aktywność użytkownika w przeglądarce, w tym interakcje z modelami GenAI. Pozwala to na:
- Audyt wykorzystania GenAI: Uzyskaj pełny obraz tego, w jaki sposób pracownicy wykorzystują narzędzia GenAI w całej organizacji.
- Wdrażanie zarządzania bezpieczeństwem: Ustal szczegółowe zasady ograniczające typy informacji, które mogą być udostępniane LLM-om.
- Zapobiegaj wyciekom danych: Blokuj próby udostępniania poufnych danych firmowych modelom GenAI.
LayerX oferuje kompleksowe rozwiązanie BDR, które pomoże Ci zabezpieczyć korzystanie z narzędzi GenAI. Analizując całą aktywność przeglądarki, LayerX może wykryć i zablokować nawet najbardziej zaawansowane próby jailbreaku, zapewniając Twojej organizacji możliwość korzystania z zalet GenAI bez narażania się na niepotrzebne ryzyko.
Monity jailbreaku dla określonych modeli
Choć opisane powyżej techniki można ogólnie zastosować w większości modeli LLM, niektóre modele mają swoje własne, wyjątkowe luki w zabezpieczeniach.
Ucieczka z więzienia sztucznej inteligencji postaci
Jak wspomniano wcześniej, sztuczna inteligencja postaci jest szczególnie podatna na wykorzystywanie osobowości. Jeśli szukasz sposobu na jailbreak sztucznej inteligencji postaci, przekonasz się, że wiele udanych prób wymaga stworzenia bardzo konkretnej i szczegółowej osobowości, którą model będzie mógł przyjąć.
Claude AI Jailbreak
Claude AI, opracowany przez firmę Anthropic, znany jest z silnych zabezpieczeń. Nie jest jednak odporny na ataki typu jailbreak. Skuteczny jailbreak Claude AI często wymaga zastosowania kombinacji natychmiastowego zaciemniania obrazu i wieloetapowego łączenia komunikatów w celu ominięcia jego zabezpieczeń.
DeepSeek AI Jailbreak
DeepSeek AI to kolejny potężny model LLM, który padł ofiarą ataków. Jailbreak DeepSeek AI często wymaga bardziej technicznego podejścia, takiego jak wykorzystanie konkretnych luk w architekturze modelu.
Rozwiązanie firmy LayerX na ataki typu jailbreak
Ataki typu jailbreak na GenAI stanowią poważne zagrożenie, które może mieć poważne konsekwencje dla organizacji. Rozumiejąc techniki stosowane przez atakujących i wdrażając wielowarstwową strategię obrony, możesz chronić swoją organizację przed tymi nowymi zagrożeniami. Obejmuje to solidną walidację danych wejściowych, ciągłe monitorowanie modeli oraz wykorzystanie rozwiązania BDR, takiego jak LayerX, w celu zabezpieczenia wszystkich interakcji użytkowników z narzędziami GenAI.
Świat jailbreaku AI to nieustanna walka między innowacją a bezpieczeństwem. Dzięki informowaniu i proaktywnemu podejściu możesz mieć pewność, że Twoja organizacja pozostanie po właściwej stronie tej bitwy.
