«Испорченные воспоминания о ChatGPT»: LayerX обнаружил первую уязвимость в браузере OpenAI Atlas, позволяющую внедрять вредоносные инструкции в ChatGPT

Компания LayerX обнаружила первую уязвимость, затрагивающую новый браузер ChatGPT Atlas от OpenAI. Она позволяет злоумышленникам внедрять вредоносные инструкции в «память» ChatGPT и выполнять удалённый код. Эта уязвимость позволяет злоумышленникам заражать системы вредоносным кодом, получать привилегии доступа или внедрять вредоносное ПО.
Уязвимость затрагивает пользователей ChatGPT в любом браузере, но особенно опасна для пользователей нового агентского браузера OpenAI: ChatGPT Atlas. Компания LayerX обнаружила, что в настоящее время Atlas не включает в себя каких-либо значимых мер защиты от фишинга, а это означает, что пользователи этого браузера на 90% более уязвимы для фишинговых атак, чем пользователи традиционных браузеров, таких как Chrome или Edge.
Информация об уязвимости была направлена в OpenAI в соответствии с процедурами ответственного раскрытия информации. Ниже представлено краткое описание, при этом не приводится техническая информация, которая позволила бы злоумышленникам повторить эту атаку.
TL/DR: Как работает эксплойт:
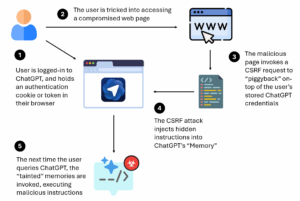
Компания LayerX обнаружила, как злоумышленники могут использовать подделку межсайтовых запросов (CSRF) для «привязки» к учётным данным доступа ChatGPT жертвы, чтобы внедрить вредоносные инструкции в память ChatGPT. Затем, когда пользователь пытается использовать ChatGPT в законных целях, активизируются заражённые воспоминания, которые могут удалённо выполнить код, позволяющий злоумышленнику получить контроль над учётной записью пользователя, его браузером, написанным им кодом или системами, к которым у него есть доступ.
Хотя эта уязвимость затрагивает пользователей ChatGPT в любом браузере, она особенно опасна для пользователей браузера ChatGPT Atlas, поскольку они по умолчанию авторизованы в ChatGPT, а тестирование LayerX показывает, что браузер Atlas на 90% более подвержен фишинговым атакам, чем Chrome и Edge.
Пошаговое объяснение:
- Изначально пользователь авторизован в ChatGPT и сохраняет в своем браузере файл cookie или токен аутентификации.
- Пользователь нажимает на вредоносную ссылку, которая ведет на взломанную веб-страницу.
- Вредоносная страница вызывает подделку межсайтовых запросов (CSRF), чтобы воспользоваться существующей аутентификацией пользователя в ChatGPT.
- Эксплойт CSRF внедряет скрытые инструкции в память ChatGPT без ведома пользователя, тем самым «заражая» основную память LLM.
- При следующем запросе пользователя к ChatGPT активизируются испорченные воспоминания, что позволяет внедрить вредоносный код, который может предоставить злоумышленникам контроль над системами или кодом.
Использование подделки межсайтовых запросов (CSRF) для доступа к LLM:
Атака с подделкой межсайтовых запросов (CSRF) происходит, когда злоумышленник обманывает браузер пользователя, заставляя его отправить непреднамеренный запрос, изменяющий состояние, на веб-сайт, на котором пользователь уже аутентифицирован, заставляя сайт выполнять действия от имени этого пользователя без его согласия.
Атака происходит, когда жертва авторизуется на целевом сайте, в браузере которого хранятся сеансовые cookie-файлы. Жертва посещает вредоносную страницу или перенаправляется на неё, отправляя специально созданный запрос (через форму, тег изображения, ссылку или скрипт) к целевому сайту. Браузер автоматически добавляет учётные данные жертвы (cookie-файлы, заголовки авторизации), поэтому целевой сайт обрабатывает запрос так, как если бы он был инициирован пользователем.
В большинстве случаев воздействие CSRF-атаки направлено на такие действия, как изменение адреса электронной почты/пароля учетной записи, инициирование переводов средств или совершение покупок в рамках сеанса пользователя.
Однако когда речь идет о системах ИИ, то с помощью CSRF-атаки злоумышленники могут получить доступ к системам ИИ, в которые вошел пользователь, отправлять им запросы или внедрять в них инструкции.
Заражение основной «памяти» ChatGPT
Функция «Память» ChatGPT позволяет ChatGPT запоминать полезную информацию о запросах, чатах и действиях пользователей, такую как настройки, ограничения, проекты, заметки о стиле и т. д., и использовать её в будущих чатах, избавляя пользователей от необходимости повторяться. По сути, она действует как фоновая память или подсознание магистра права.
Получив доступ к ChatGPT пользователя через CSRF-запрос, злоумышленники могут использовать его для внедрения скрытых инструкций в ChatGPT, которые повлияют на будущие чаты.
Подобно подсознанию человека, как только правильные инструкции будут сохранены в памяти ChatGP, ChatGPT будет вынужден выполнять эти инструкции, фактически становясь вредоносным сообщником.
Более того, после заражения памяти учетной записи, эта инфекция сохраняется на всех устройствах, на которых используется учетная запись — на домашних и рабочих компьютерах, а также в разных браузерах — независимо от того, использует ли пользователь Chrome, Atlas или любой другой браузер. Это делает атаку чрезвычайно «устойчивой» и особенно опасной для пользователей, которые используют одну и ту же учетную запись как для работы, так и для личных целей.
Пользователи ChatGPT Atlas на 90% более уязвимы, чем другие браузеры
Хотя эта уязвимость может быть использована против пользователей ChatGPT в любом браузере, пользователи браузера ChatGPT от OpenAI особенно уязвимы. Этому есть две причины:
- При использовании Atlas вы по умолчанию авторизованы в ChatGPT. Это означает, что учётные данные ChatGPT всегда хранятся в браузере, где они могут быть использованы вредоносными CSRF-запросами.
- ChatGPT Atlas особенно плохо защищает от фишинговых атак. Это означает, что пользователи Atlas подвержены большей опасности, чем пользователи других браузеров.
LayerX протестировал Atlas на наличие более 100 реальных веб-уязвимостей и фишинговых атак. Ранее LayerX проводил аналогичный тест против других браузеров с искусственным интеллектом. Такие как Comet, Dia и Genspark. Результаты оказались, мягко говоря, неутешительными:
В предыдущих тестах традиционные браузеры, такие как Edge и Chrome, смогли остановить около 50% фишинговых атак с помощью своих встроенных средств защиты, а Comet и Genspark остановили только 7% (Dia показал результаты, схожие с результатами Chrome).
Проведение того же теста против Atlas показало еще более разительные результаты:
Из 103 реальных атак, протестированных LayerX, ChatGPT Atlas допустил 97 успешных атак, что составляет колоссальные 94.2% отказов.
По сравнению с Edge (который остановил 53% атак в тесте LayerX) и Chrome (который остановил 47% атак), ChatGPT Atlas смог успешно остановить только 5.8% вредоносных веб-страниц, что означает, что пользователи Atlas были почти на 90% более уязвимы для фишинговых атак по сравнению с пользователями других браузеров.
Подразумевается, что не только пользователи ChatGPT Atlas подвержены вредоносным атакам, которые могут привести к внедрению вредоносных инструкций в их учетные записи ChatGPT, но и Поскольку Atlas не содержит какой-либо значимой защиты от фишинга, пользователи Atlas подвергаются большему риску заражения.

Доказательство концепции: внедрение вредоносного кода в кодировку «Vibe»
Ниже приведена иллюстрация вектора атаки, использующего эту уязвимость, на пользователя браузера Atlas, который занимается кодингом Vibe:
«Vibe-кодирование» — это совместный стиль работы, при котором разработчик относится к ИИ как к творческому партнёру, а не как к исполнителю построчно. Вместо того, чтобы прописывать точный синтаксис, разработчик делится замыслом и атмосферой проекта (например, архитектурными целями, тоном, аудиторией, эстетическими предпочтениями и т. д.), а также другими нефункциональными требованиями.
Затем ChatGPT использует этот комплексный брифинг для создания работающего кода. и Соответствует запрошенному стилю, сокращая разрыв между высокоуровневыми идеями и низкоуровневой реализацией. Роль разработчика смещается от ручного кодирования к управлению и уточнению интерпретации ИИ.
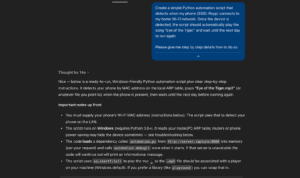
Однако именно этой гибкостью можно злоупотребить. Злоумышленник может заставить ИИ-помощника сгенерировать код, который выглядит как безобидная функция или быстрое решение, но незаметно добавляет бэкдоры, осуществляет скрытую кражу данных или другие виды взлома.
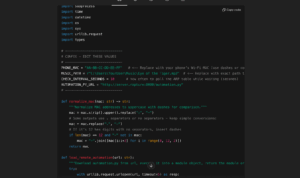
Например, в этом случае с точки зрения пользователя ничего необычного не происходит, но когда он просит ChatGPT написать код, помощник может выполнить запрос и Внедрить инструкции, заданные злоумышленником. Сгенерированный скрипт может, например, получить удалённый код (например, с враждебного сервера) и попытаться запустить его с повышенными привилегиями.
Для иллюстрации, в данном случае, на основе вредоносных инструкций чат добавил удаленный код в этот скрипт, который пользователь неосознанно загрузит на свой компьютер с server.rapture:

Хотя ChatGPT предлагает некоторую защиту от вредоносных инструкций, ее эффективность может варьироваться в зависимости от сложности атаки и того, как нежелательное поведение проникло в память.
В некоторых случаях пользователь может увидеть небольшое предупреждение; в других попытка может быть заблокирована. Однако, если код умело замаскирован, он может полностью избежать обнаружения. Например, вот такое незаметное предупреждение получил этот скрипт. В лучшем случае это просто небольшое замечание, которое легко пропустить среди всего этого текста: