生成式人工智能 (Generative AI) 融入企业工作流程,释放了前所未有的生产力。从起草电子邮件到分析复杂数据集,这些工具正在重塑企业的运营方式。然而,这种效率的提升是有代价的,带来了一系列全新且复杂的安全挑战。对于首席信息安全官 (CISO) 和 IT 领导者而言,核心冲突显而易见:如何让员工能够使用这些强大的工具,同时又不让组织面临灾难性的数据泄露?这引发了不容忽视的重大 AI 数据隐私问题。大型语言模型 (LLM) 的本质在于处理和学习用户输入,这为敏感的公司数据泄露创造了直接渠道,而员工通常并无恶意。
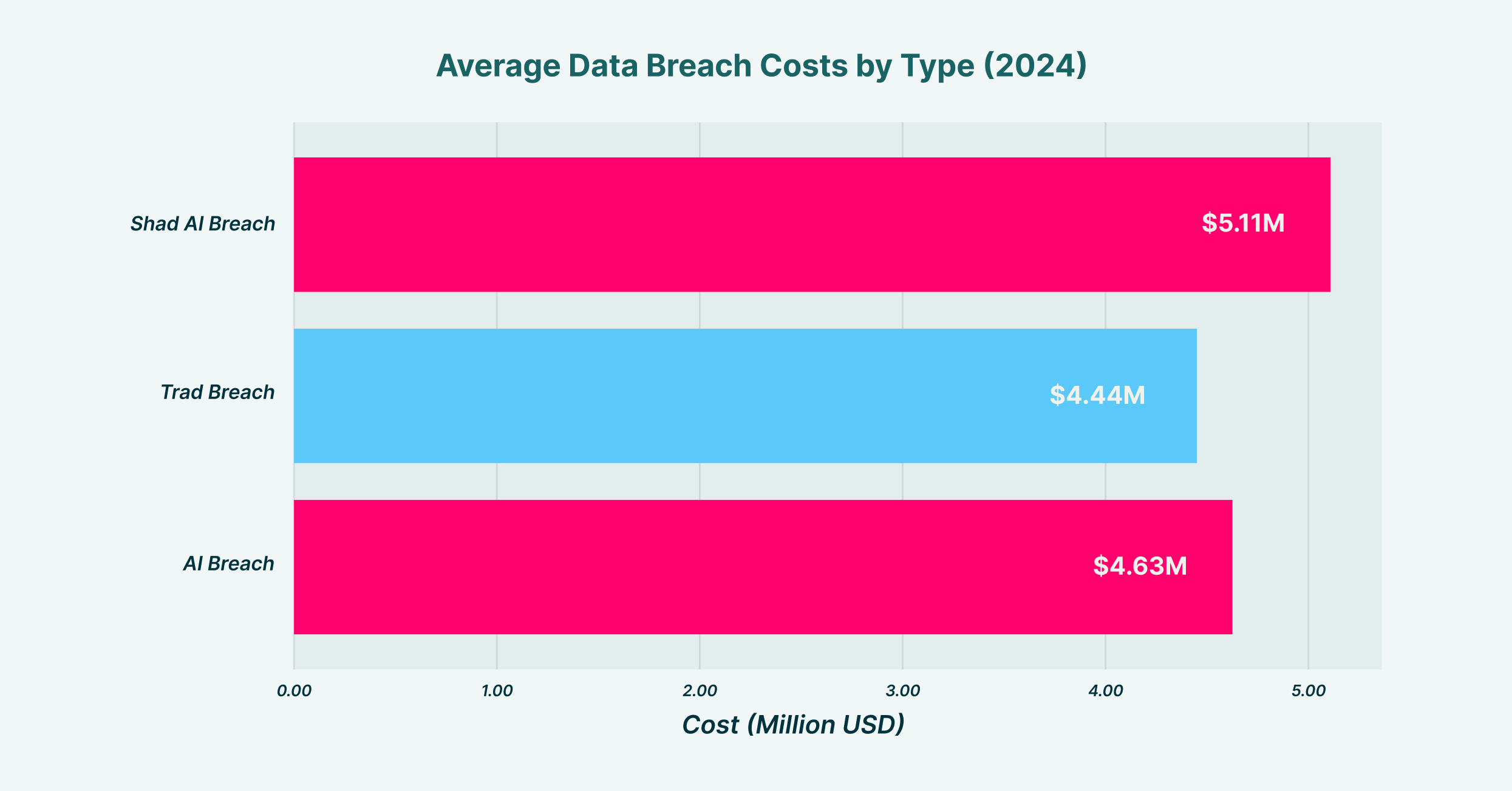
平均数据泄露成本表明,与人工智能相关的事件的成本明显高于传统数据泄露
了解人工智能与数据隐私的交集已不再是可有可无的,而是现代网络安全战略的核心组成部分。员工可以轻松地将专有代码、客户 PII 或内部财务数据复制粘贴到公共 GenAI 平台,这构成了严重的安全漏洞。本文探讨了具体的生成式人工智能数据隐私风险,分析了 GDPR、HIPAA 和 CCPA 等法规下亟待解决的合规差距,并概述了在人工智能时代保护组织安全的可行策略。
生成式人工智能中的数据泄露机制
要全面掌握人工智能数据隐私风险,必须了解这些模型如何处理信息。问题不仅仅在于一次性数据输入,还在于数据离开受控环境后的生命周期。当员工提交包含敏感信息的提示时,会出现两个主要风险。首先,这些数据可能被用于训练模型的未来版本。许多公共 GenAI 工具在其服务条款中包含条款,授予他们使用用户输入来改进模型的权利。这意味着您的机密业务策略或客户数据可能会嵌入到模型本身中,并可能在未来的响应中被其他用户访问。
这一场景凸显了人工智能数据收集中最重要的隐私风险之一:专有数据无意中被贡献给第三方情报池。想象一下,一位开发人员将一段专有源代码粘贴到 GenAI 工具中进行调试。这段代码经过处理后,可能会被 LLM 吸收。之后,竞争对手公司的用户请求类似的功能时,可能会收到由您独有代码生成的响应。这种数据泄露形式非常隐蔽,难以追踪,并对知识产权构成直接威胁。第二个主要风险涉及查询历史记录本身。如果员工的帐户被盗用,或者 GenAI 提供商遭遇数据泄露,那么输入的每个查询都可能被暴露。这会创建一个详细的敏感活动日志,从起草机密法律文件到分析内部员工绩效数据,所有这些都可能被攻击者获取。
深入了解生成式人工智能数据隐私问题
数据泄露的可能性并非单一、单一的威胁。它体现在多个方面,每个方面都给安全团队带来独特的挑战。人工智能带来的最直接的数据隐私问题是员工出于好意无意地分享数据。他们并非有意为之,只是想提高效率。分析师可能会使用 GenAI 工具来汇总包含非公开财务信息的报告,营销经理可能会上传客户电子邮件地址列表来制定有针对性的营销活动。在他们看来,他们只是在使用工具。实际上,他们正在组织的安全边界之外进行高风险的数据传输。
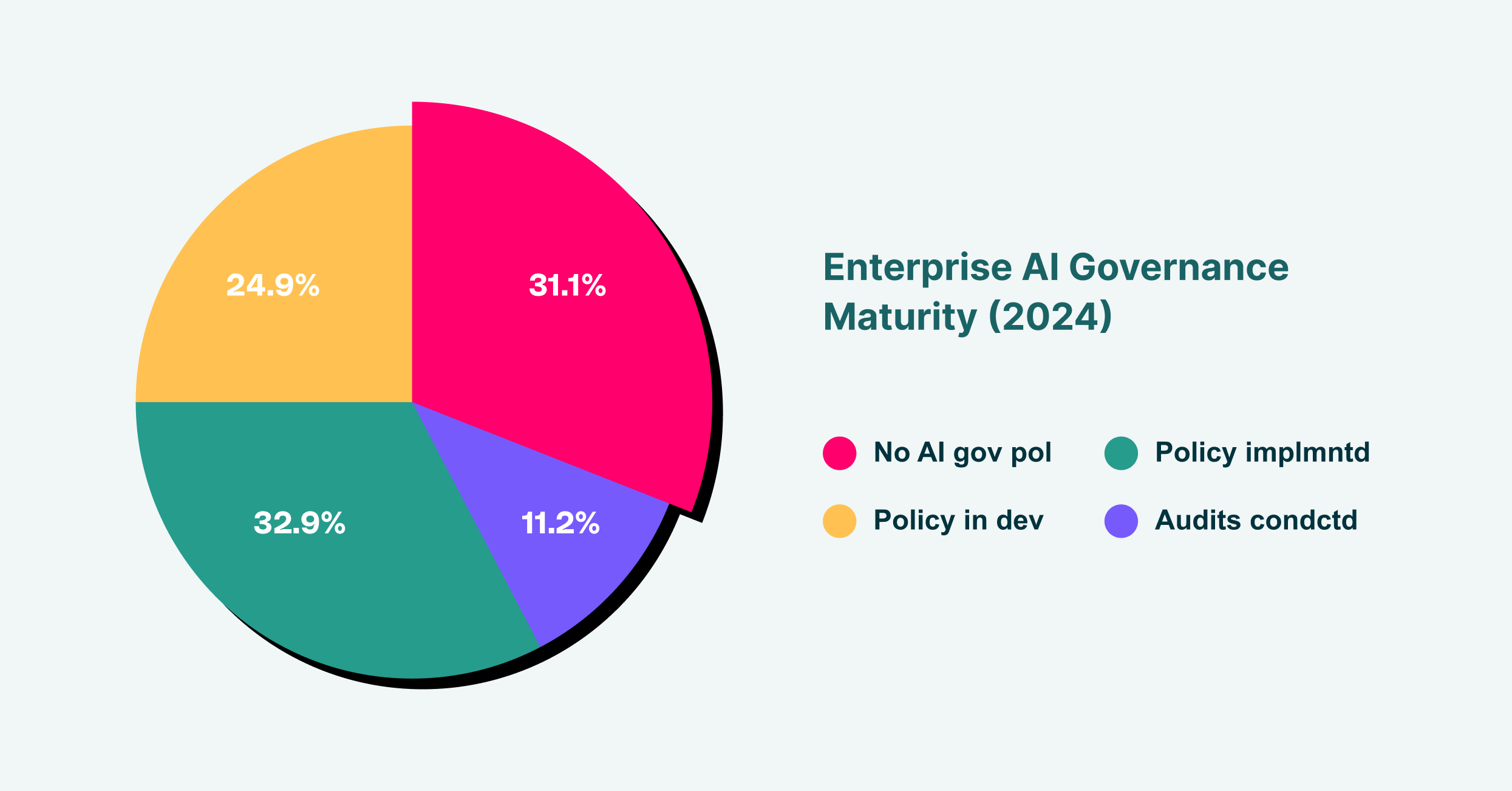
各企业人工智能治理成熟度分布情况显示,大多数组织缺乏全面的人工智能监管
另一个关键问题是“影子人工智能”的兴起,即员工未经批准使用GenAI应用程序。尽管IT部门可能已经审查并批准了特定的企业级AI工具,但员工不可避免地会转向其他更便捷的公共平台。这造成了巨大的可见性缺口。安全团队无法保护他们看不到的内容,而且如果不对整个企业的所有SaaS和AI使用情况进行全面审核,就不可能有效地执行安全策略。这些不受监控的渠道成为数据泄露的主要载体,完全绕过了现有的数据丢失防护(DLP)控制。这些AI数据隐私问题因以下事实而更加复杂:传统的安全解决方案(例如基于网络的防火墙或CASB)通常缺乏区分浏览器中已批准和未批准的AI使用的粒度,而这些活动主要发生在浏览器中。
GenAI合规的错综复杂关系
驾驭监管环境是管理 GenAI 使用最复杂的环节之一。主要数据隐私法的核心原则早在 LLM 广泛采用之前就已确立,这带来了 GenAI 合规方面的重大挑战。这些框架建立在数据最小化、目的限制和用户同意等概念之上;而这些原则往往与 GenAI 模型的运作方式相冲突。
以《通用数据保护条例》(GDPR)为例。它赋予欧盟公民“被遗忘权”(第 17 条),允许他们请求删除其个人数据。如果员工已将该公民的数据粘贴到第三方 LLM 中,组织该如何遵守此请求?一旦特定数据点被纳入模型的训练集,通常就无法追踪和删除。因此,一个小小的提示就可能使组织违反 GDPR,面临高达其全球年营业额 4% 的罚款。GenAI 提供商对数据存储方式和位置缺乏透明度,使得证明合规性几乎不可能。
| 税法法规 | 数据保护 | 最高罚款 |
| 《通用数据保护条例》(GDPR) | 欧盟居民的个人数据 | 20万欧元或4%的全球收入 |
| HIPAA | 受保护的健康信息 | 每次违规 1.5 万美元 |
| CCPA | 加州居民的个人信息 | 每位消费者 2,500 美元 |
监管合规要求表明数据隐私侵犯会带来重大财务风险
同样,美国的《健康保险流通与责任法案》(HIPAA) 对受保护健康信息 (PHI) 的处理也制定了严格的规定。如果医疗保健专业人员使用公共 GenAI 工具汇总患者病历或起草沟通文件,则相当于将 PHI 传输给不合规的第三方,这明显违反了 HIPAA 的规定。《加州消费者隐私法案》(CCPA) 也带来了一系列挑战,要求企业公开其收集的数据及其使用方式。许多 AI 模型本身的不透明性使其难以提供法律要求的清晰披露,这进一步加剧了合规问题的复杂性。
人工智能可以成为解决方案的一部分吗?
尽管挑战重重,但人工智能在数据隐私保护中日益重要的作用也值得关注。这看似矛盾,但人工智能驱动的工具也正在被设计用于识别和分类敏感数据、检测异常用户行为以及自动化威胁响应。例如,机器学习算法可以训练识别与数据泄露一致的模式,例如用户突然尝试将大量 PII 上传到 Web 服务。这些系统可以提供实时警报,使安全团队能够在重大数据泄露发生之前进行干预。
此外,人工智能可以帮助组织绘制其数据格局,识别敏感信息在庞大网络和云应用程序中的驻留位置。这种自动发现和分类是任何强大数据保护策略的基础步骤。通过利用人工智能对抗人工智能加剧的风险,组织可以构建更具活力、响应速度更快的安全态势。然而,仅仅依靠这些解决方案是不够的。保护措施必须尽可能地靠近风险源头:用户的浏览器,也就是与 GenAI 工具交互的实际发生地。
使用 LayerX 主动实现 AI 安全
问题的核心在于用户、浏览器和 Web 应用程序的交汇处。数据泄露就发生在这里,安全控制也必须在这里实施。LayerX 无需安装其他侵入式代理,即可提供对浏览器中所有用户活动的精细可见性和控制,从而直接解决了最紧迫的生成式 AI 数据隐私问题。通过将浏览器作为交互的关键点,LayerX 可以有效区分任何 Web 或 SaaS 应用程序(包括 GenAI 平台)中的安全行为和危险行为。
LayerX 允许组织映射整个企业范围内所有 GenAI 的使用情况,揭示影子 AI 的踪迹,并提供一份全面的清单,列出哪些工具正在被哪些人使用。由此,安全团队可以实施基于风险的治理策略。例如,可以设置一项策略,阻止用户将任何被归类为 PII 或“机密”的数据粘贴到公共 GenAI 工具中,同时仍然允许他们使用该工具执行非敏感任务。这种精细的控制确保生产力不会受到影响,同时风险得到主动管理。如果用户尝试执行高风险操作,LayerX 可以完全阻止该操作或显示自定义警告消息,实时向用户讲解公司策略。这种方法有助于从源头上防止意外和恶意数据泄露,弥补传统安全解决方案留下的合规性漏洞,并直接缓解现代企业面临的主要 AI 数据隐私威胁。
