A rápida integração da IA Generativa (GenAI) aos fluxos de trabalho corporativos promete um aumento significativo na produtividade. Da geração de código à análise de mercado, os Modelos de Linguagem Ampla (LLMs) estão se tornando copilotos indispensáveis. No entanto, essa crescente dependência introduz um risco sutil, porém profundo: alucinações de IA. Não se trata de meros bugs ou erros simples; representam casos em que um modelo de IA gera informações convincentes, mas totalmente falsas, sem sentido ou desconexas. Para analistas de segurança, CISOs e líderes de TI, compreender a mecânica e as consequências dessas fabricações é o primeiro passo para mitigar um novo e complexo vetor de ameaças.
À medida que as organizações incentivam o uso da GenAI para se manterem competitivas, elas inadvertidamente abrem a porta para cenários em que resultados falhos de IA podem levar a decisões de negócios desastrosas, violações de segurança de dados e falhas de conformidade. O desafio é que os erros da GenAI frequentemente parecem plausíveis, tornando-os difíceis de serem detectados pelo usuário comum. Um funcionário pode pedir a um LLM para resumir uma nova regulamentação de conformidade, apenas para receber uma resposta confiante que omite uma cláusula crítica ou inventa uma inexistente. O ganho de produtividade é imediatamente anulado pelo custo da remediação. Por que isso está acontecendo e o que pode ser feito para proteger a empresa? A resposta está em compreender a natureza dos próprios modelos e implementar uma supervisão robusta. 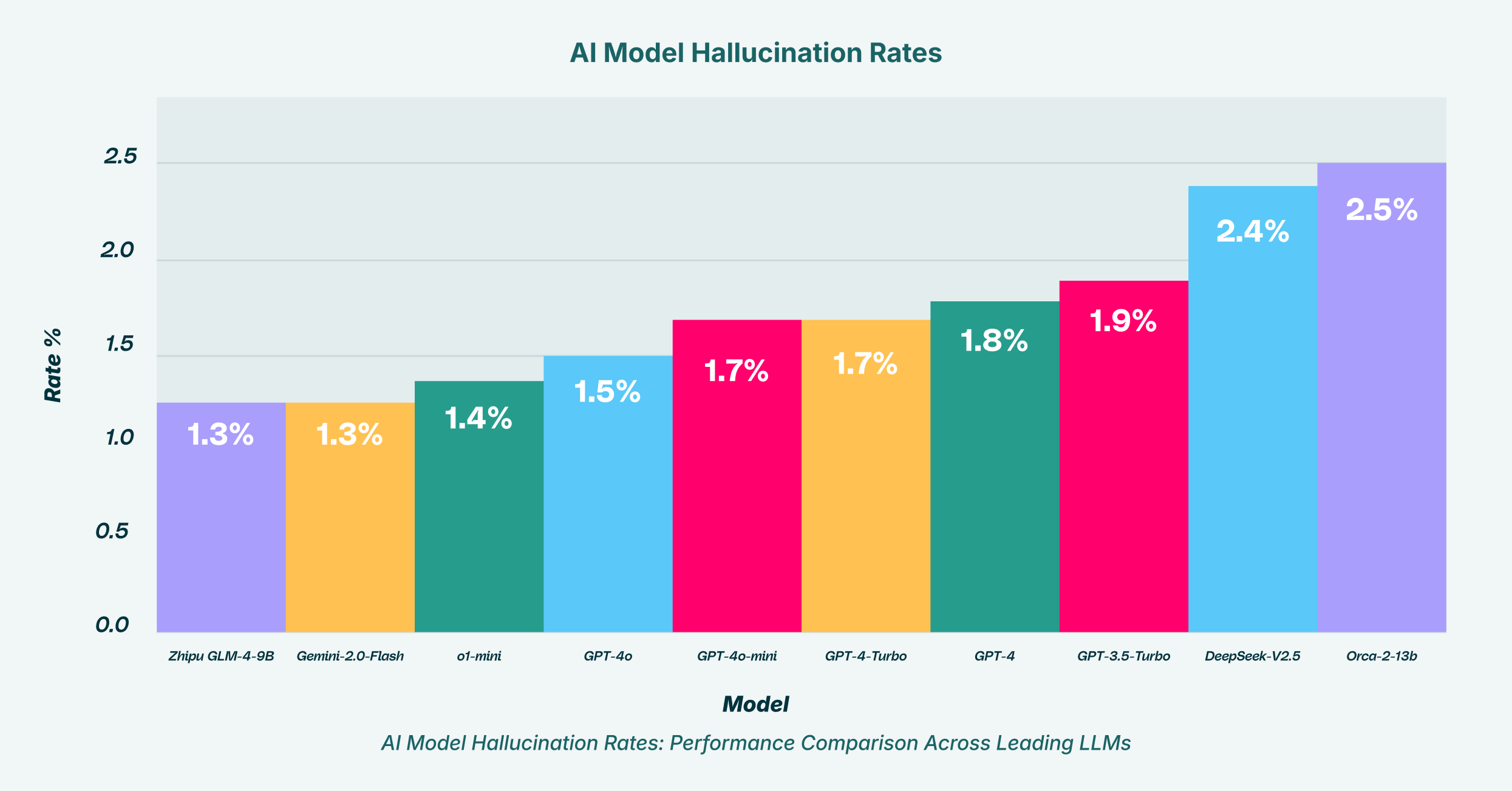
Desconstruindo alucinações de IA
Em sua essência, uma alucinação de IA ocorre quando um modelo gera uma saída que não é justificada por seus dados de treinamento ou pela entrada fornecida. LLMs são sistemas probabilísticos; eles são projetados para prever a próxima palavra mais provável em uma sequência, não para entender a verdade ou falsidade. Esse processo, embora poderoso, pode levá-los a inventar fatos, criar citações para fontes inexistentes ou gerar código com falhas de segurança sutis, mas críticas. Essas não são falhas aleatórias, mas são inerentes ao funcionamento dos modelos da geração atual.
O problema é ainda mais grave quando se discutem alucinações de LLM, que são específicas de modelos de linguagem. Esses modelos aprendem padrões, gramática e estilo a partir de vastos conjuntos de dados coletados da internet. Se os dados de treinamento contiverem vieses, imprecisões ou informações conflitantes, o modelo os aprenderá e os reproduzirá. Ele pode declarar com segurança um fato histórico incorreto ou mesclar detalhes de dois eventos distintos em uma única narrativa fictícia. Imagine um analista de marketing usando uma ferramenta GenAI para pesquisa competitiva. A ferramenta pode gerar um relatório detalhando o lançamento de um novo produto de um concorrente, completo com recursos fabricados e uma data de lançamento fictícia, levando o analista a desenvolver uma contraestratégia baseada em premissas totalmente falsas.
Essas alucinações modelo não constituem um problema único e monolítico. Elas se manifestam de diversas formas:
- Invenção factual: O modelo gera detalhes específicos e incorretos, como nomes, datas ou estatísticas.
- Fabricação de fontes: a IA cria citações para artigos, estudos ou casos legais que não existem, dando um falso ar de autoridade às suas alegações.
- Contradição lógica: O modelo produz uma resposta que se contradiz ou viola princípios lógicos básicos.
O problema central é que esses modelos carecem de um verdadeiro mecanismo de raciocínio. Eles são mestres da imitação, não da compreensão. Para uma empresa, isso significa que cada saída de uma ferramenta GenAI deve ser tratada com desconfiança até ser verificada.
As raízes técnicas das alucinações modelo
Para combater eficazmente os riscos da IA, é essencial compreender por que as alucinações com modelos ocorrem em nível técnico. Essas alucinações não são meras peculiaridades aleatórias, mas decorrem da arquitetura fundamental e das metodologias de treinamento dos LLMs. Elas são, em muitos aspectos, uma característica da natureza probabilística desses sistemas, não apenas um bug a ser corrigido. Os modelos são projetados para gerar sequências de texto coerentes e gramaticalmente corretas, mas carecem de um verificador de fatos interno ou de uma conexão com uma base de conhecimento verificada em tempo real.
Vários fatores-chave contribuem para a prevalência de erros do GenAI:
- Geração Probabilística: Um LLM não "sabe" coisas no sentido humano. Quando solicitado, ele calcula a probabilidade da próxima palavra, dadas as palavras anteriores. Uma alucinação pode ocorrer se o modelo seguir um caminho estatisticamente provável, mas factualmente incorreto. Ele consiste essencialmente em compor a frase que soa mais plausível, não a mais verdadeira.
- Limitações dos Dados de Treinamento: Os modelos são tão bons quanto os dados com os quais são treinados. Se o conjunto de dados de treinamento estiver desatualizado, contiver vieses inerentes ou tiver escassez de informações sobre um tópico específico, o modelo provavelmente "preencherá as lacunas" com detalhes inventados. Ele pode ter amplo conhecimento até a data limite de treinamento, mas alucinará informações sobre eventos que ocorreram posteriormente.
- Erros de codificação e decodificação: Durante o processo de conversão de ideias complexas em representações matemáticas (vetores) e de volta em texto legível por humanos, nuances podem se perder. Isso pode levar o modelo a interpretar incorretamente um prompt ou gerar uma resposta semanticamente semelhante, mas contextualmente incorreta.
- Overfitting: Em alguns casos, um modelo pode estar "superotimizado" em seus dados de treinamento, fazendo com que ele memorize frases ou padrões específicos. Quando solicitado com algo semelhante, mas não idêntico, ele pode reverter para uma resposta memorizada, mas inadequada, criando uma saída alucinatória.
Esses fundamentos técnicos demonstram que as alucinações com o LLM são um problema sistêmico. Simplesmente pedir aos funcionários que "tenham cuidado" é uma estratégia inadequada. Sem uma camada de controle técnico, a organização permanece exposta às consequências dessas falhas inerentes ao modelo. Isso é especialmente verdadeiro à medida que os funcionários usam cada vez mais ferramentas GenAI baseadas em navegador e aplicativos SaaS para tarefas diárias, muitas vezes fora do escopo da segurança de TI tradicional.
Consequências reais dos erros da GenAI
Os riscos teóricos das alucinações com IA se traduzem em consequências tangíveis e de alto risco para as empresas modernas. Esses erros não se limitam a imprecisões triviais; eles podem desencadear incidentes de segurança, corroer a integridade dos dados e criar responsabilidades significativas de conformidade. O navegador, como interface principal para a maioria dos aplicativos GenAI e SaaS, tornou-se um campo de batalha crítico onde esses riscos se manifestam.
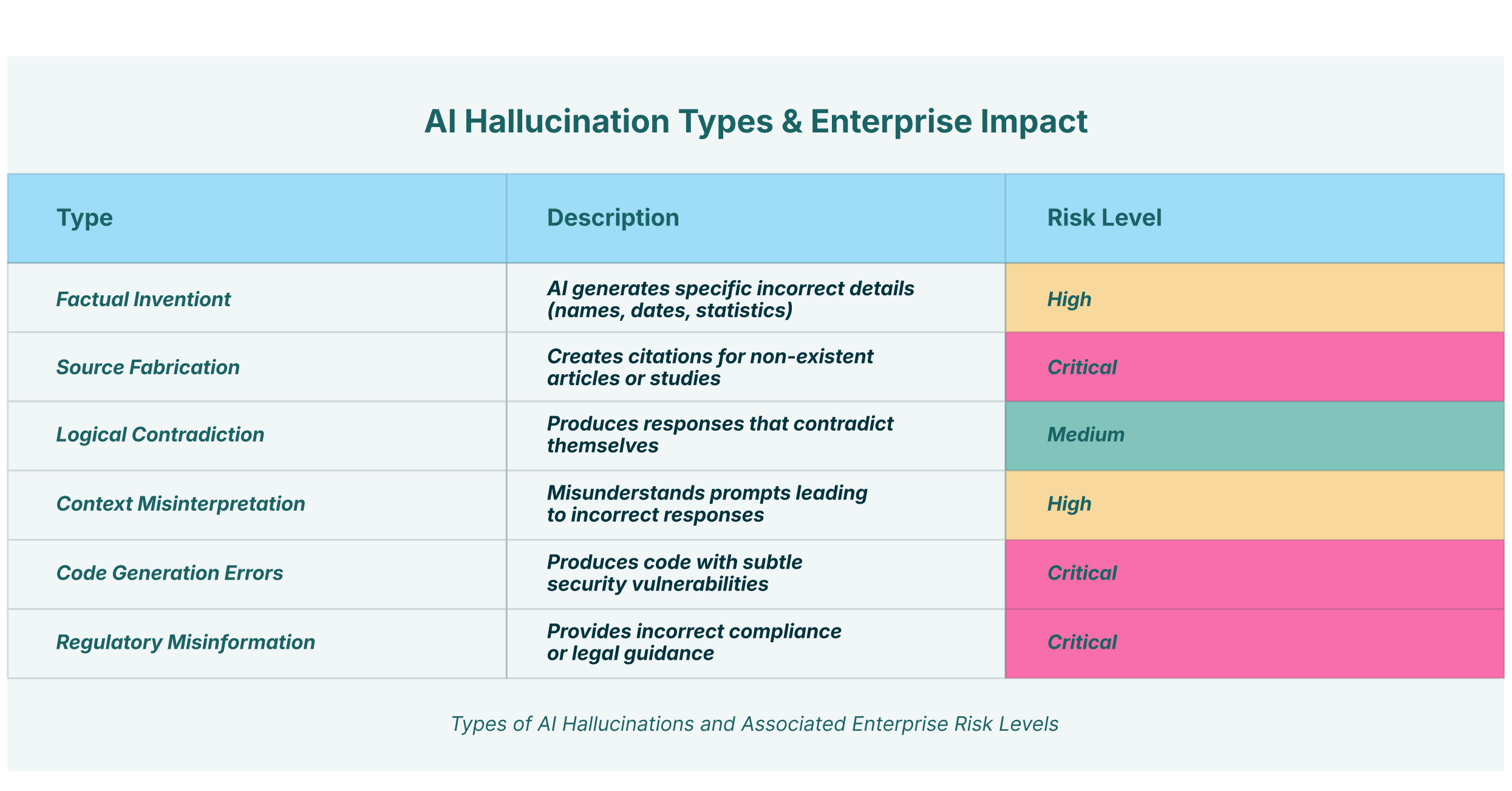
Imagine um cenário em uma instituição financeira. Um analista júnior usa uma extensão GenAI de terceiros não verificada em seu navegador, uma forma de "shadow SaaS", para acelerar a due diligence de um potencial investimento. Ele cola dados financeiros confidenciais e não públicos na interface de bate-papo. O modelo, em sua resposta, sofre de uma das alucinações clássicas de modelos: gera um resumo que deturpa os passivos da empresa-alvo, retratando uma situação financeira mais saudável do que a realidade. Agindo com base nesses dados falhos, a empresa toma uma decisão de investimento ruim, levando a perdas financeiras diretas. O problema é duplo: um erro estratégico foi cometido com base em um erro da GenAI, e dados corporativos confidenciais foram exfiltrados para um LLM de terceiros não confiável, criando um grave evento de vazamento de dados.
É aqui que a solução da LayerX para a segurança da GenAI se torna essencial. Ao fornecer uma auditoria completa de todos os aplicativos SaaS, incluindo a TI paralela não autorizada, a LayerX permite que as organizações identifiquem quando e onde os funcionários estão usando essas ferramentas. Guardrails granulares e baseados em risco podem ser aplicados. Por exemplo, uma política pode ser aplicada para bloquear a inserção de PII ou dados financeiros confidenciais em chatbots da GenAI, evitando o vazamento inicial de dados.
Considere outro caso, desta vez em uma organização de saúde. Um médico, em busca de informações sobre uma interação medicamentosa rara, consulta um chatbot de IA médica. A IA, propensa a alucinações de LLM, fabrica uma resposta com confiança, alegando que não há interações conhecidas. O médico, pressionado pelo tempo, aceita a resposta. O potencial de danos ao paciente é imenso. A facilidade de uso de aplicativos SaaS torna isso um risco de alta frequência. A capacidade da LayerX de controlar a atividade do usuário nesses aplicativos é fundamental. Ela pode rastrear e governar interações com serviços de compartilhamento de arquivos e unidades online, evitando o vazamento acidental ou malicioso de informações confidenciais, incluindo relatórios falhos gerados por IA que poderiam se espalhar por toda a organização.
Esses cenários hipotéticos destacam um padrão:
- Os usuários adotam novas ferramentas GenAI para produtividade, muitas vezes sem aprovação oficial, criando um ecossistema “SaaS paralelo”.
- Essas ferramentas são suscetíveis a alucinações de IA, produzindo resultados convincentes, mas perigosamente incorretos.
- A interação, que acontece dentro do navegador, ignora muitos controles tradicionais de segurança de rede, levando à exfiltração de dados e à tomada de decisões ruins.
Sem uma solução que ofereça visibilidade e controle diretamente no navegador, as empresas estão voando às cegas. Elas não têm as ferramentas para proteger adequadamente o uso de SaaS, o que as deixa vulneráveis às ameaças duplas da TI paralela e da IA não confiável.
A necessidade crítica de camadas de validação de IA
Considerando que as alucinações com modelos são uma parte inerente da tecnologia GenAI atual, as organizações não podem simplesmente esperar que os criadores dos modelos resolvam o problema. A responsabilidade de implementar salvaguardas recai sobre a empresa. É aqui que o conceito de camadas de validação de IA se torna um imperativo estratégico. Uma camada de validação é um sistema ou processo que fica entre o usuário e o modelo de IA para verificar, sanitizar ou bloquear o conteúdo gerado pela IA antes que ele possa ser acionado ou causar danos.
Uma camada de validação de IA não visa substituir a IA, mas sim envolvê-la em uma estrutura de segurança. Ela atua como um cinto de segurança cognitivo, protegendo o usuário e a organização das consequências de erros inesperados do GenAI. Essas camadas podem assumir diversas formas, desde simples filtros baseados em palavras-chave até sistemas mais complexos que cruzam a saída da IA com bases de conhecimento internas confiáveis. No entanto, para a maioria dos casos de uso corporativo, a camada de validação mais eficaz é aquela que opera onde o risco é mais agudo: o navegador do usuário.
A LayerX opera como uma camada de validação de IA poderosa e prática por meio de sua extensão de navegador empresarial. Ela fornece a governança de segurança que falta no modelo SaaS direto ao usuário. Em vez de depender das promessas do provedor de IA ou da diligência do usuário, a LayerX aplica a política no ponto de interação.
- Mapeamento do Uso do GenAI: O LayerX permite que a organização descubra e mapeie todas as ferramentas GenAI em uso, incluindo o SaaS shadow. Essa visibilidade é a base de qualquer estratégia de segurança. Não é possível proteger o que não se pode ver.
- Aplicação da Governança de Segurança: Uma vez mapeado o uso, os CISOs podem aplicar controles granulares. Políticas podem ser definidas para restringir os tipos de dados compartilhados com os LLMs, impedindo que informações corporativas confidenciais sejam inseridas em modelos externos, onde podem vazar ou ser usadas para treinamento. Por exemplo, uma regra pode ser criada para suprimir ou bloquear qualquer conteúdo identificado como PII antes que ele saia do navegador.
- Restringindo Atividades Perigosas: A solução pode monitorar comportamentos de risco, como baixar e executar código gerado por uma IA que pode conter vulnerabilidades devido a alucinações de LLM. Também pode impedir o upload de documentos confidenciais para aplicativos de compartilhamento de arquivos não autorizados, frustrando um canal importante para vazamento de dados.
Ao focar no navegador, a LayerX cria efetivamente um perímetro de segurança em torno do elemento mais imprevisível da pilha corporativa moderna: a interação entre um usuário humano e uma IA de terceiros. Ela aceita a realidade de que alucinações de IA ocorrerão e fornece os controles necessários para gerenciar esse risco. Ela transforma o navegador de um elo fraco em um ponto de estrangulamento para a aplicação da segurança, garantindo que os benefícios de produtividade do GenAI possam ser obtidos sem expor a organização a perigos inaceitáveis. Para qualquer setor, mas especialmente para os regulamentados, como o financeiro e o de saúde, essa camada de validação não é mais um luxo, mas um componente essencial de uma arquitetura de segurança moderna.
