Generative AI (GenAI) has rapidly transitioned from a novel technology to a core component of enterprise operations. From accelerating code development to revolutionizing customer engagement, its applications are expanding at an unprecedented rate. Yet, this powerful wave of innovation carries a significant undercurrent of risk. The very models that generate insightful, human-like text can also produce harmful, biased, and toxic content, introducing substantial legal, ethical, and business challenges. The issue of GenAI toxicity is not a fringe concern; it is a central obstacle to the safe and scalable adoption of AI.
For security analysts, CISOs, and IT leaders, understanding and mitigating this risk is paramount. It’s not enough to simply embrace GenAI’s productivity benefits; organizations must also erect strong defenses against its potential for harm. This requires a thorough examination of the origins of this toxicity, the tangible risks it poses, and the essential controls necessary for effective governance.
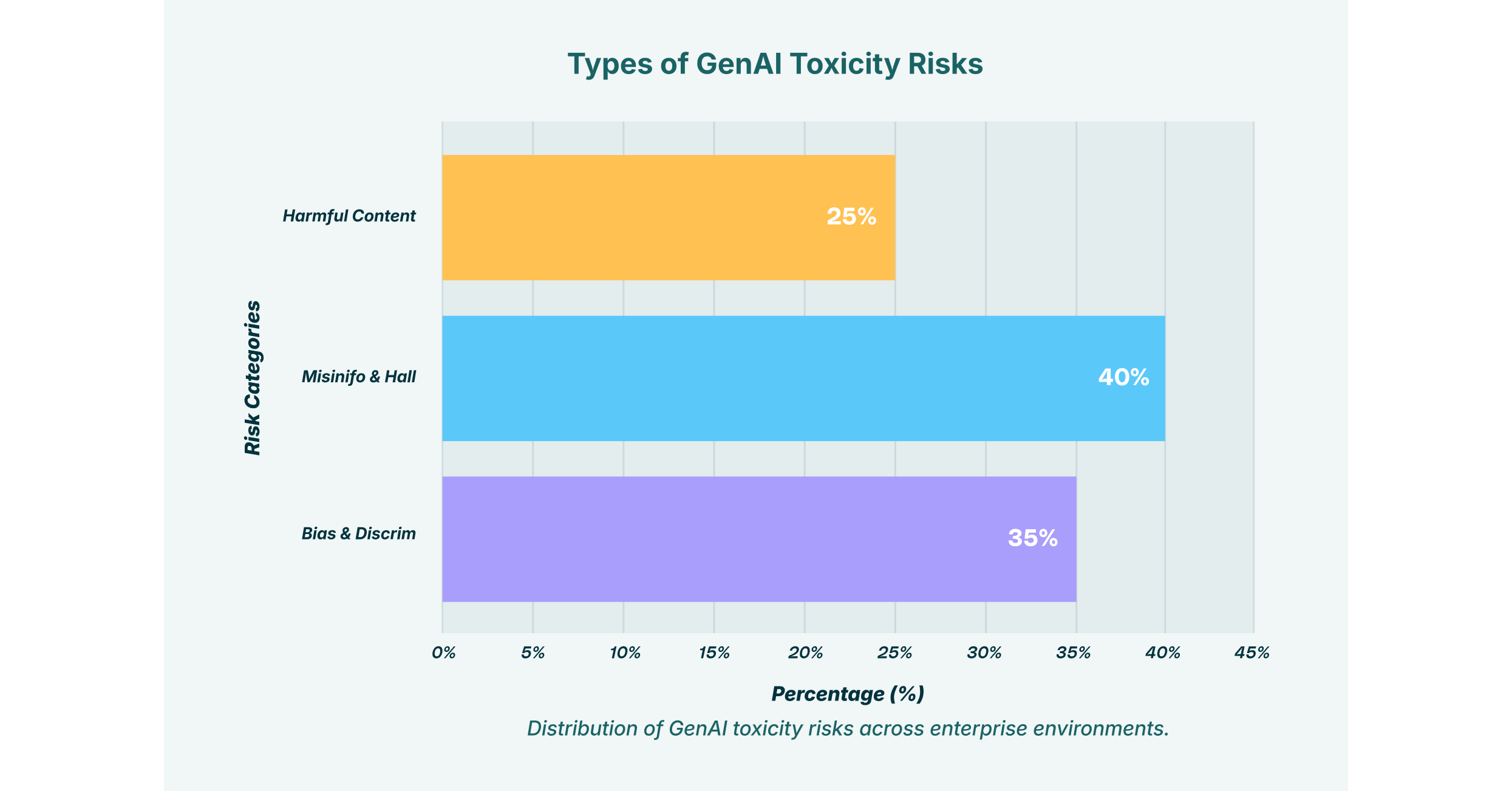 Understanding GenAI Toxicity: More Than Just Bad Words
Understanding GenAI Toxicity: More Than Just Bad Words
The term GenAI toxicity extends far beyond simple profanity or hate speech. It encompasses a wide spectrum of harmful content, including subtle but damaging biases, the propagation of misinformation, and the generation of inappropriate content that can violate corporate policies and societal norms. The origins of this toxicity are as complex as the models themselves.
At its core, the problem often begins with the training data. Large Language Models (LLMs) are trained on immense datasets scraped from the internet, a digital reflection of humanity that includes its best knowledge and its worst prejudices. If the training data is skewed, the model will inevitably learn and replicate those biases, leading to unfair or discriminatory LLM outputs. This could manifest as a recruiting tool that favors one gender over another or a financial advice bot that offers different loan terms based on ethnicity.
Compounding this issue is the “black box” nature of many GenAI systems. The intricate, multi-layered neural networks that power these models make it incredibly difficult to trace a specific output back to its cause. This lack of transparency poses a significant hurdle for GenAI governance, as auditing a model for fairness and safety presents a substantial technical challenge. Furthermore, malicious actors can exploit these systems through adversarial attacks like “prompt injection” or “jailbreaking,” where cleverly crafted inputs are used to bypass the model’s built-in safety filters and coerce it into generating harmful content.
The Tangible Risks of Toxic LLM Outputs
When a GenAI model produces toxic content, the consequences are far from theoretical. For an enterprise, the damage can be immediate and severe, impacting everything from brand reputation to operational stability.
- Brand and Reputational Damage: Public trust is fragile. An incident involving a toxic AI can shatter it in an instant. For instance, when Figma’s GenAI tool was found to be plagiarizing Apple’s copyrighted designs, it caused significant brand embarrassment that required a public retraction. In another case, a Canadian airline was held legally responsible for misleading information provided by its customer service chatbot, demonstrating that organizations are accountable for their AI’s mistakes.
- Legal and Compliance Violations: Toxic or biased LLM outputs can lead to serious legal trouble. Discriminatory outputs may violate fairness-in-hiring laws, while those that leak or misuse personal data can run afoul of regulations like GDPR or HIPAA. In highly regulated industries such as finance and healthcare, the compliance stakes are exceptionally high.
- Business and Operational Disruption: The impact of flawed LLM outputs is not just external. Internally, reliance on inaccurate or biased GenAI-generated information can disrupt workflows, corrupt decision-making processes, and spread misinformation throughout an organization. Imagine a marketing team acting on flawed market analysis from a GenAI tool or a developer implementing insecure code suggested by an AI assistant. The operational fallout could be immense.
- Heightened Security Threats: Beyond generating toxic content, GenAI can be weaponized to create sophisticated security threats. Attackers can prompt models to write highly convincing phishing emails, generate polymorphic malware that evades traditional detection, or craft scripts for social engineering attacks. This represents a new frontier of GenAI-powered exfiltration and attack orchestration that security teams must be prepared to confront.
Detection: Identifying Bias and Toxicity
To control GenAI toxicity, you must first be able to see it. Detecting harmful content and underlying biases within LLMs is a complex, multi-faceted discipline that combines statistical analysis, behavioral testing, and human oversight. Organizations cannot afford to treat their models as infallible; they must implement a continuous and rigorous process for LLM bias detection.
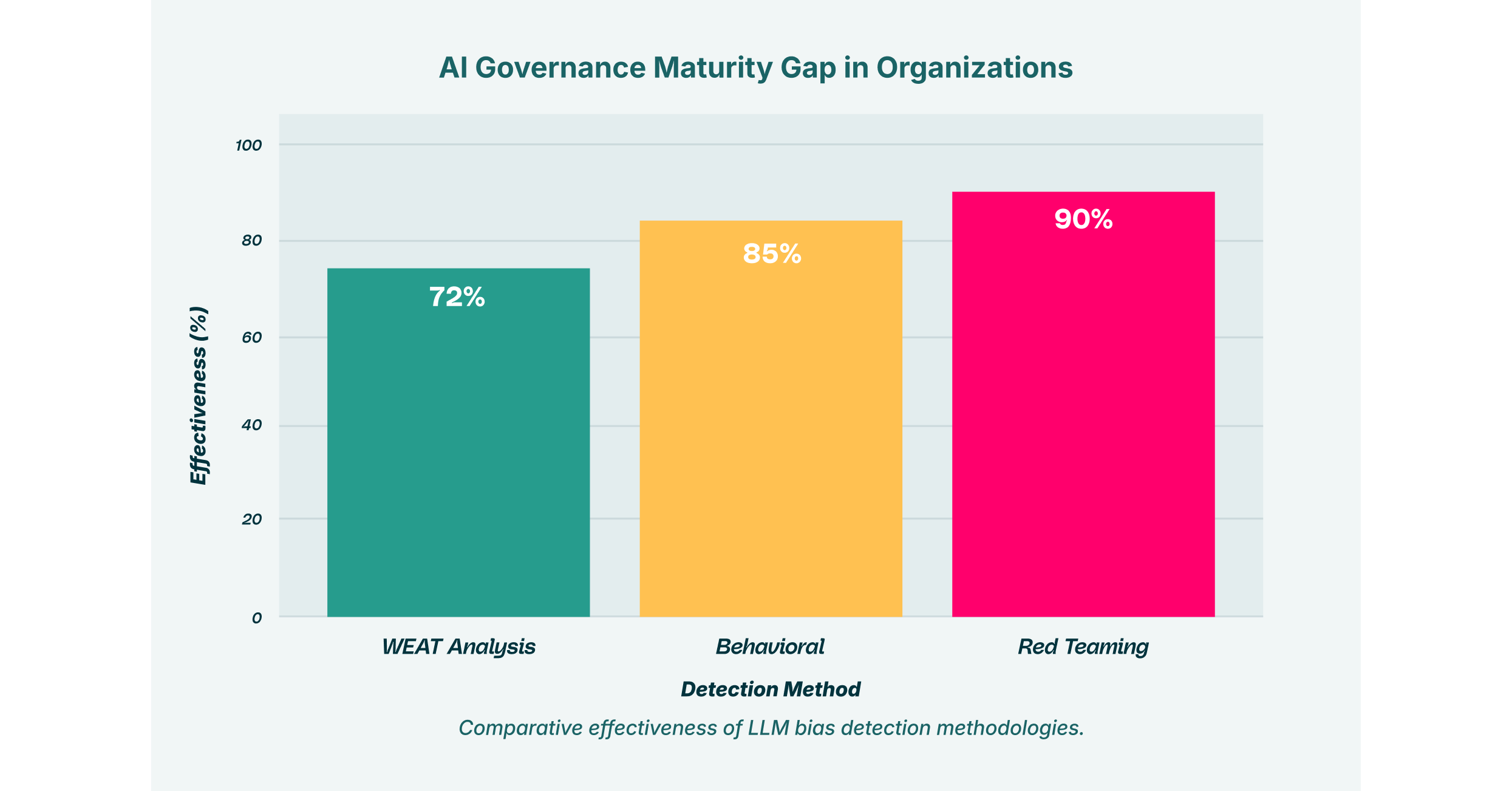
One of the more technical approaches involves statistical and embedding-based tests. Techniques like the Word Embedding Association Test (WEAT) analyze the internal representations of the model to measure the strength of association between different concepts, for example, the proximity of words related to certain professions to specific genders. By using metrics like cosine similarity, data scientists can statistically quantify biases that may not be apparent on the surface.
Another critical method is behavioral testing, or “probing.” This involves using structured benchmarks and carefully designed questions to systematically query the model for biased responses across a range of sensitive categories, including age, religion, disability, and nationality. Emerging techniques like Uncertainty Quantification (UQ) and Explainable AI (XAI) are also showing promise in helping to unearth unanticipated biases by analyzing a model’s confidence levels and decision-making pathways.
However, automated tools alone are insufficient. Red teaming, a process where security experts actively attempt to trick a model into producing harmful content, is essential for uncovering vulnerabilities that automated tests might miss. This adversarial approach is complemented by establishing robust feedback loops, where human evaluators and end-users can report biased or inappropriate content, providing the data needed for ongoing model refinement and retraining.
AI Content Moderation: The First Line of Defense
While LLM bias detection focuses on analyzing the model itself, AI content moderation is the practical, real-time application of these insights to filter inputs and outputs. It serves as the frontline defense, preventing harmful content from ever reaching end-users or being processed by the model in the first place.
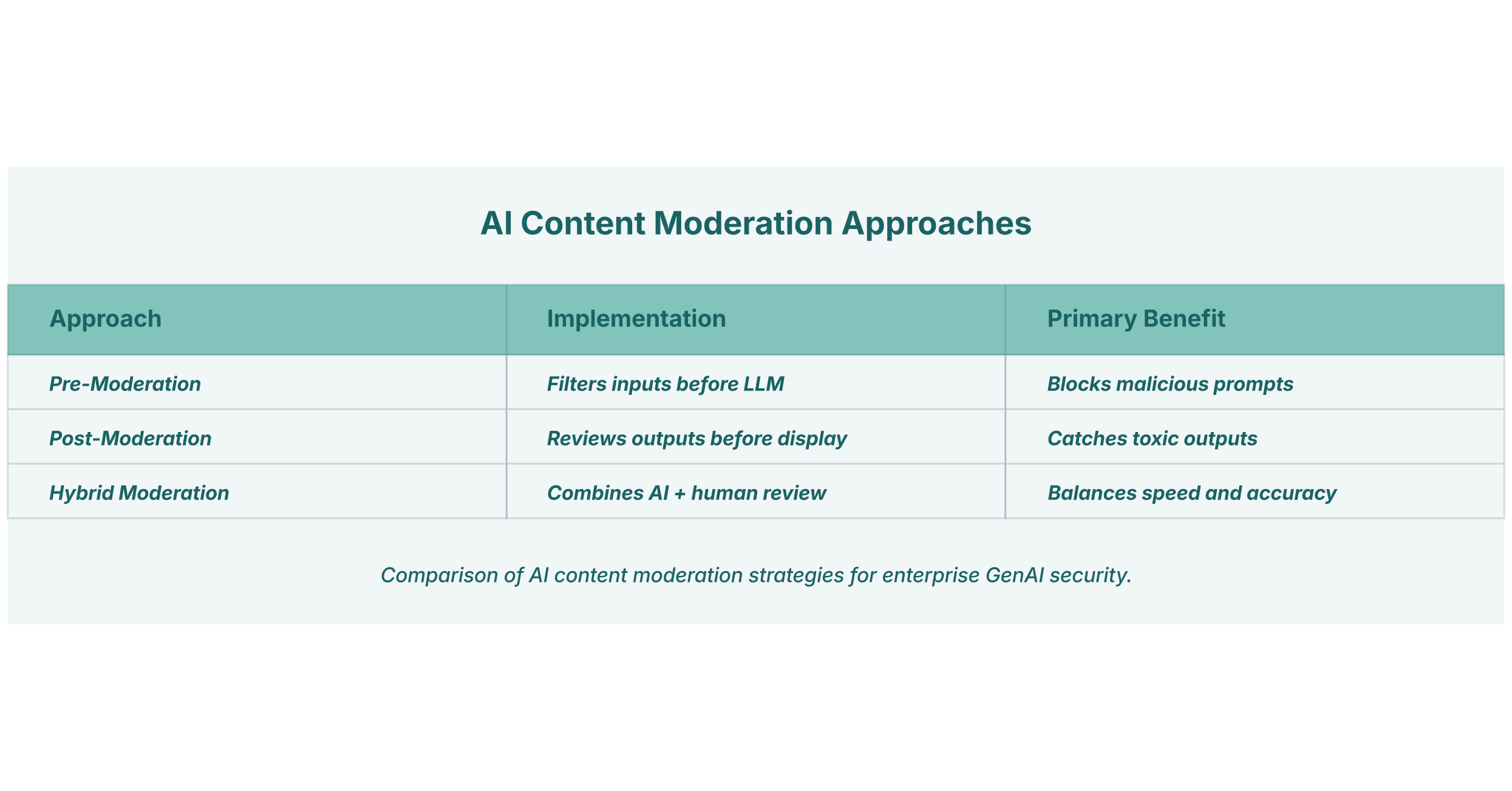
Effective AI content moderation strategies typically involve several layers:
- Pre-Moderation: This technique involves scanning user inputs before they are sent to the LLM. By using Natural Language Processing (NLP) to check for keywords, threatening language, or patterns associated with prompt injection attacks, organizations can block malicious or inappropriate queries at the source.
- Post-Moderation: Just as important is reviewing the LLM outputs after they are generated but before they are displayed to the user. This step acts as a final safety check to catch any harmful, biased, or toxic content the model may have produced, despite other safeguards.
- Hybrid Moderation: The most effective and widely adopted approach is hybrid moderation, which combines the speed and scale of automated AI filters with the nuance and contextual understanding of human moderators. The AI handles the high volume of clear-cut cases, while ambiguous or sensitive content is escalated for human review. This ensures both efficiency and high accuracy.
Some platforms are also moving towards proactive moderation, where sophisticated AI systems are designed to identify and contain the spread of harmful content before it can gain visibility, creating a safer digital environment from the outset.
 Implementing Controls: A Governance-Led Approach
Implementing Controls: A Governance-Led Approach
Detecting toxicity and moderating content are crucial reactive measures, but a truly effective strategy is proactive and rooted in strong governance. For CISOs and IT leaders, the goal is to create a framework of policies and technical controls that enables the safe use of GenAI across the enterprise.
It all starts with a comprehensive GenAI governance plan. This requires establishing a clear AI use policy that defines what is permitted, what is restricted, and the specific procedures for using AI with sensitive or proprietary data. This policy should be built on the core foundations of transparency, accountability, and ethical usage, ensuring that all AI activities align with the organization’s values and legal obligations.
With a policy in place, the next step is to implement GenAI guardrails, the technical controls that enforce these rules in practice. These guardrails include input and output filtering systems that utilize AI content moderation to block toxic content, as well as strict access controls that limit the use of powerful GenAI tools to authorized personnel.
This is where browser-level security becomes indispensable. Many of the most significant GenAI risks arise from the “Shadow SaaS” ecosystem, where employees independently use public GenAI applications within their browsers without official oversight or sanctioning. A secure enterprise browser extension provides the critical visibility and control needed to manage this risk. Imagine a scenario where an employee attempts to paste sensitive client data into a public chatbot. A browser-level security solution, such as the one offered by LayerX, can analyze the data and the context of the destination site, and either block the action outright or display a warning to the user. This capability is crucial for preventing the exfiltration of sensitive PII and intellectual property, enforcing SaaS security policies directly at the point of user interaction.
Finally, GenAI is not a “set and forget” technology. The models evolve, new threats emerge, and usage patterns change. Continuous monitoring of model behavior is essential to detect performance drift and identify new vulnerabilities. This must be paired with clear feedback loops that empower the security team and end-users to report inappropriate content or other issues, ensuring that the organization’s defenses adapt as quickly as the technology itself.
GenAI offers immense opportunities, but it also presents a complex and dynamic set of risks. The challenge of GenAI toxicity, in all its forms, is not insurmountable, but it demands a strategic, multi-layered defense. By combining advanced LLM bias detection techniques, effective AI content moderation, and a strong governance framework enforced by technical controls, organizations can navigate this new ecosystem. The objective is not to block innovation but to enable it safely. Solutions that provide visibility and control at the browser level are a critical piece of this puzzle, offering a practical way to manage the unpredictable nature of LLM outputs and secure the next wave of enterprise productivity.
