In the digital economy, data is the new oil. But what happens when that oil is being siphoned off without your knowledge? Explore the growing threat of AI-driven data scraping, where automated agents extract sensitive or proprietary information from websites, APIs, or platforms without consent. It outlines the risks to privacy, intellectual property, and competitive advantage, along with strategies for detection and prevention. The silent, sophisticated theft orchestrated by advanced AI scraping techniques represents a significant and escalating threat to enterprises worldwide. This is not the clumsy, easily-blocked bot activity of the past. Today’s threat is an intelligent automated agent, capable of mimicking human behavior with chilling precision to steal your most valuable digital assets.
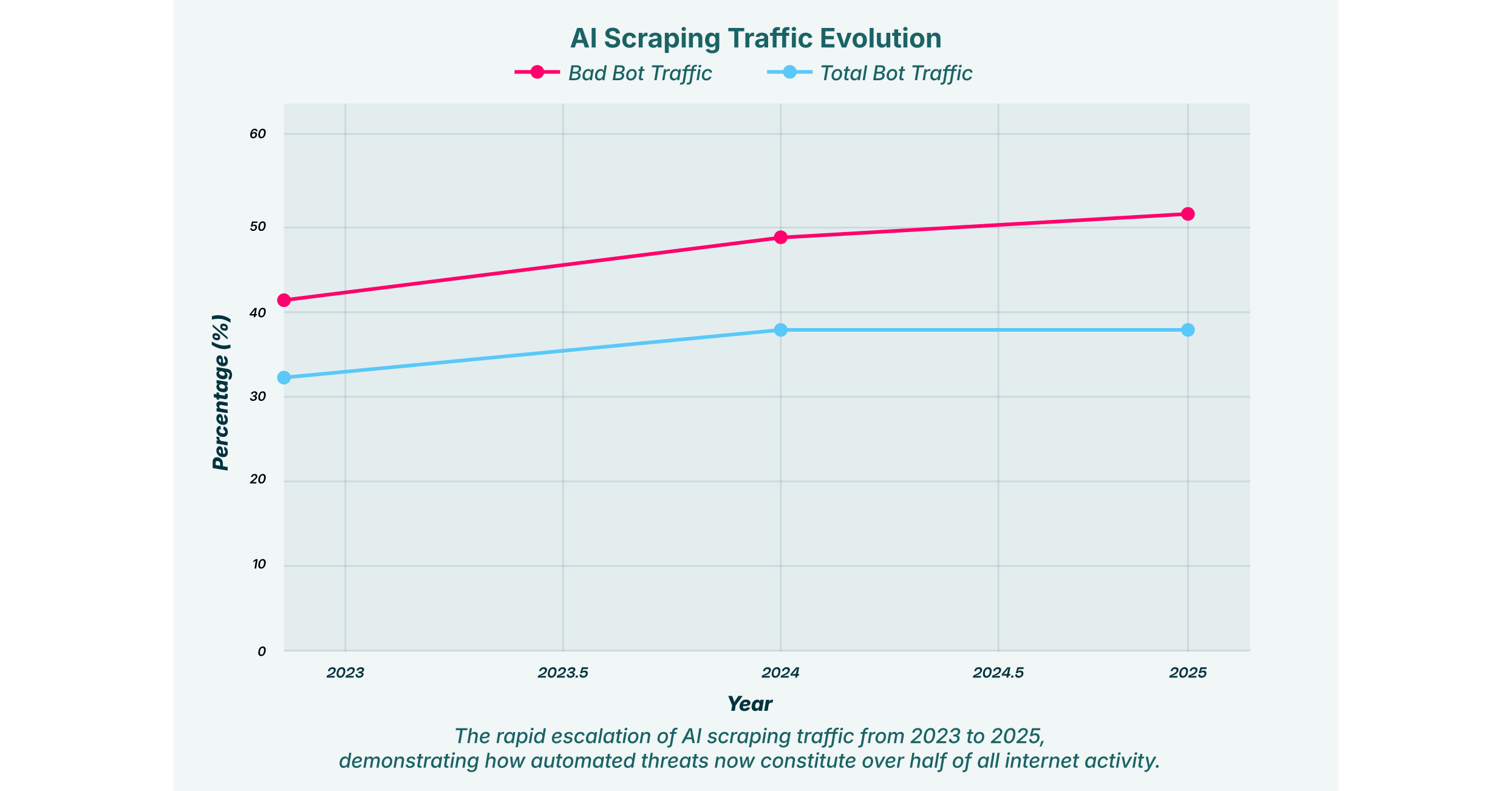
These attacks move beyond simple data harvesting. They target the very core of a company’s competitive advantage, from pricing models and customer lists to proprietary code and strategic plans. As organizations increasingly depend on web applications and SaaS platforms, the browser has become the main stage for these covert operations. Understanding the mechanics of AI scraping is the first step toward building a resilient defense.
From Brute Force to Finesse: The Evolution of Data Scraping
Traditional web scraping was often a numbers game. Attackers deployed simple scripts from a single IP address to bombard a website with requests, grabbing whatever public-facing data they could. These bots were noisy and followed predictable patterns, making them relatively easy to identify and block through rate limiting or IP blacklisting. Security teams could hold the line with conventional perimeter defenses.
That line has now been breached.
Modern AI scraping operates on a different level of sophistication. These advanced scrapers are designed for stealth and persistence, using machine learning to navigate complex web environments just as a human would. They can:
- Dynamically Adapt: When a website’s structure changes, an AI-powered scraper can adapt in real time without human intervention, ensuring the data flow is uninterrupted.
- Mimic Human Behavior: These agents randomize their browsing patterns, simulate mouse movements, and solve complex CAPTCHAs that were once the gold standard for bot detection. They appear as legitimate user traffic, slipping past all but the most advanced security filters.
- Distribute Attacks: Instead of coming from a single IP, attacks are distributed across vast residential proxy networks, making IP-based blocking completely ineffective. Each request looks like it’s coming from a different, genuine user.
Imagine a competitor deploying an automated agent to constantly monitor your e-commerce platform. It doesn’t just scrape prices once a day. It learns your dynamic pricing algorithms, identifies your most popular products by tracking user engagement metrics, and even exfiltrates customer reviews to analyze sentiment. The intellectual property behind your market strategy is reverse-engineered and used against you, all without a single alarm bell ringing.
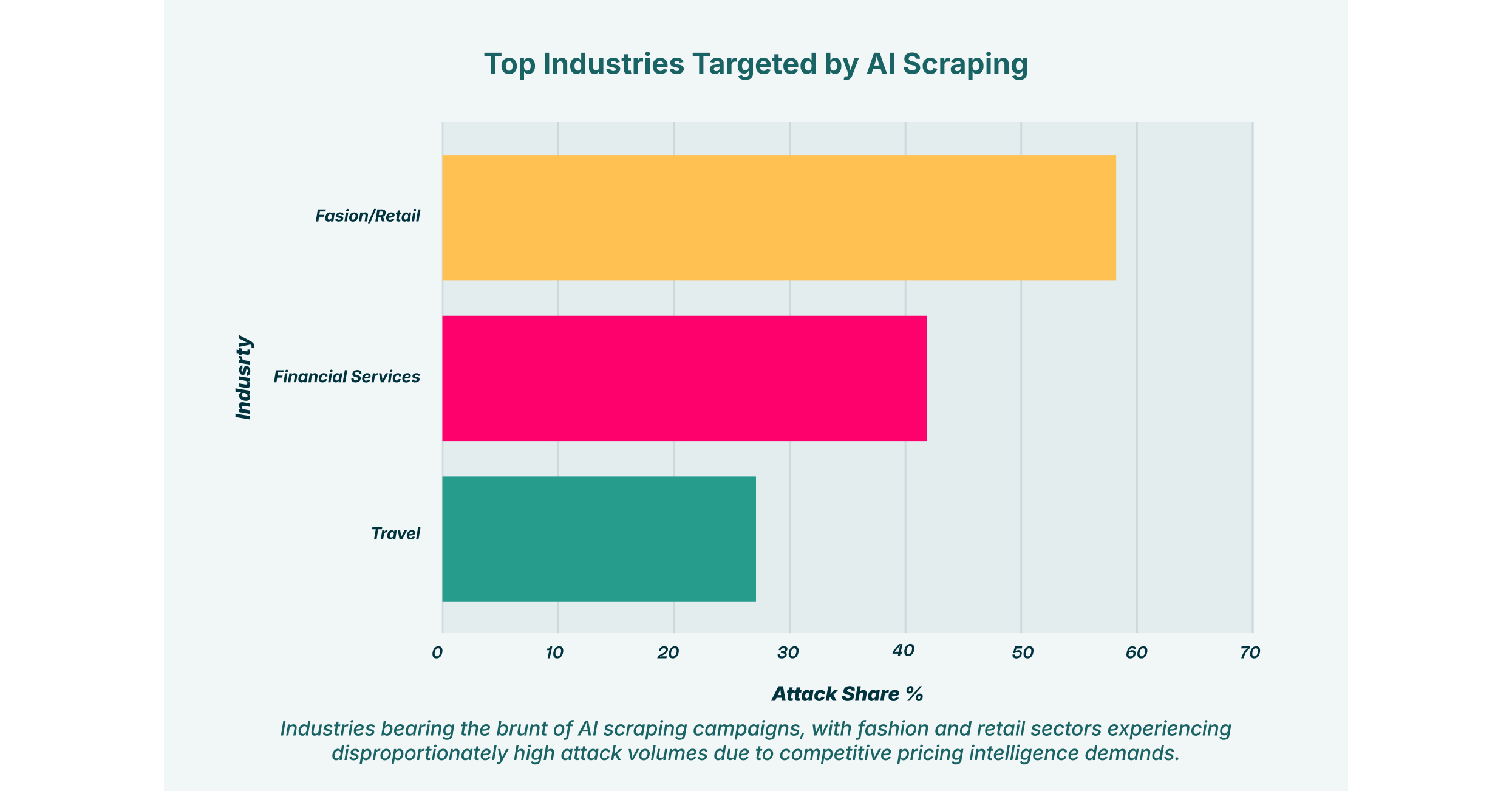 The High-Stakes Risks of Unchecked AI Scraping
The High-Stakes Risks of Unchecked AI Scraping
The consequences of a successful AI scraping campaign extend far beyond losing a competitive edge. The operational, financial, and reputational damages can be catastrophic, touching every part of the business. The core risks cluster around the theft of two critical asset types: intellectual property and sensitive data.
The Erosion of Intellectual Property
For many companies, their intellectual property is their most valuable asset. This includes everything from source code and product designs to marketing strategies and internal knowledge bases. AI scraping poses a direct threat to this foundation. Consider these scenarios:
- SaaS Platform Replication: A rival company can use an automated agent to systematically map out your entire SaaS application. It scrapes feature sets, user interface elements, and workflow logic. With this blueprint, they can rapidly develop a competing product, erasing your first-mover advantage and market differentiation.
- Content and SEO Sabotage: Digital media and content-driven businesses are particularly vulnerable. Scrapers can steal entire libraries of articles, images, and videos, republishing them on spam sites. This not only constitutes theft but can also severely damage your search engine rankings by creating duplicate content issues.
- Proprietary Algorithm Theft: Businesses that rely on unique algorithms, such as financial trading firms, logistics companies, or recommendation engines, are prime targets. An automated agent can input thousands of data points and analyze the outputs to reverse-engineer the underlying model, effectively stealing the “secret sauce” of the business.
This relentless erosion of intellectual property is a silent killer, slowly draining a company’s innovative capacity and market position.
The Exfiltration of Sensitive Data
While some scrapers target proprietary business logic, others are after a more directly monetizable prize: sensitive data. As employees interact with countless web apps and cloud services through their browsers, they create a vast attack surface for data exfiltration. An automated agent, often delivered via a seemingly benign browser extension, can sit undetected within a user’s browser, waiting for the perfect moment to strike.
This is where the browser-to-cloud attack surface becomes a critical security blind spot. An employee might access a corporate CRM, a healthcare portal, or a financial system. The agent, running with the user’s own authenticated credentials, can then systematically scrape and exfiltrate:
- Personally Identifiable Information (PII): Customer names, addresses, contact details, and government ID numbers.
- Financial Data: Credit card numbers, bank account details, and corporate financial records.
- Protected Health Information (PHI): Patient records and other data protected under regulations like HIPAA.
A single breach of sensitive data can lead to crippling regulatory fines, legal liabilities, and a complete loss of customer trust. When the exfiltration is performed by a stealthy automated agent, the breach might not be discovered for months, compounding the damage.
The New Frontier: GenAI API Scraping
The recent explosion of Generative AI has opened up a new and highly specialized vector for malicious data extraction: GenAI API scraping. Organizations are increasingly integrating Large Language Models (LLMs) into their workflows and products through APIs. These APIs, while powerful, represent a new and attractive target for sophisticated attackers.
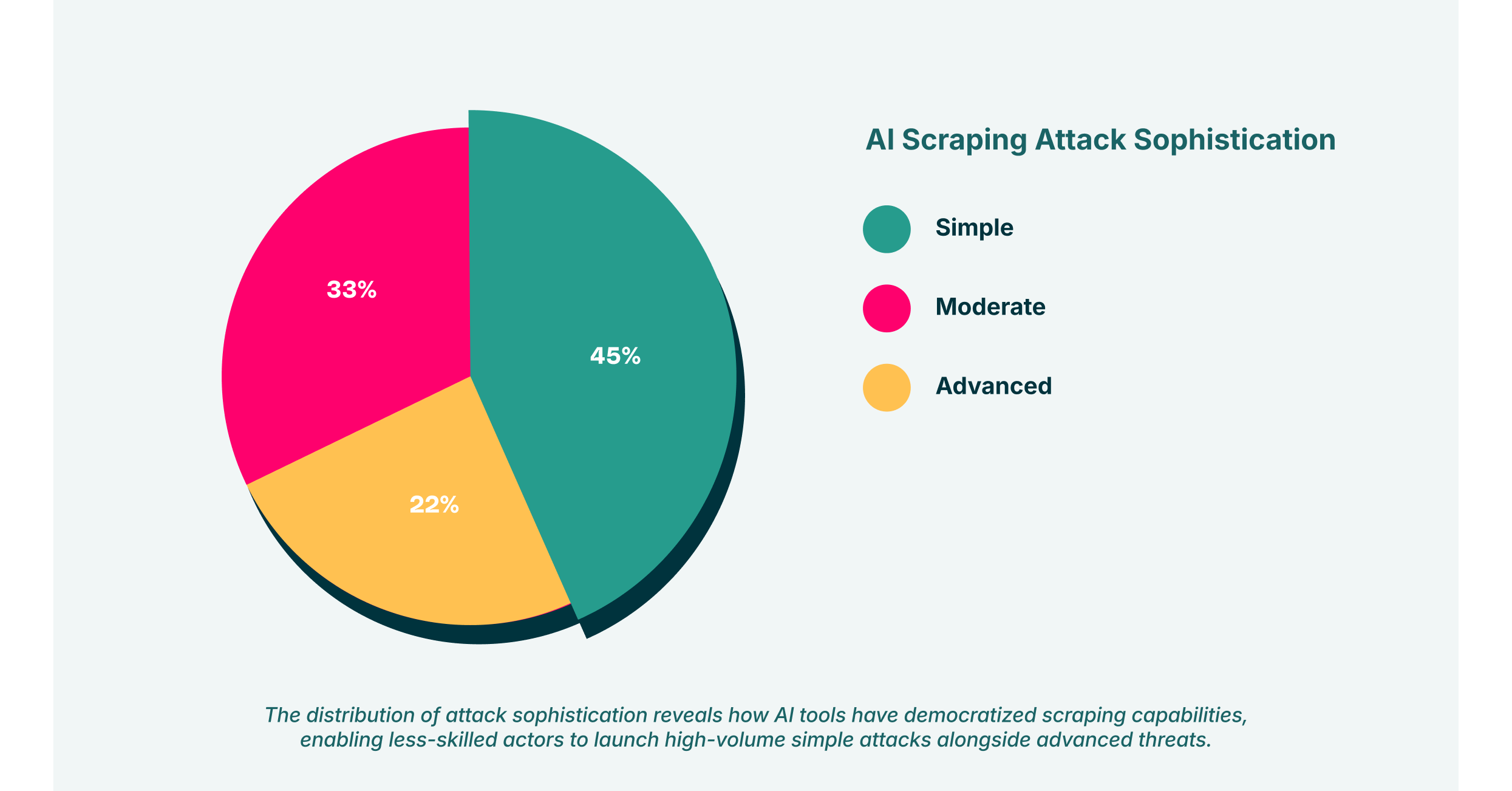
GenAI API scraping is not about stealing surface-level website content. It’s about attacking the AI model itself. Through carefully crafted API calls, an automated agent can:
- Steal Proprietary Models: By systematically querying a custom-trained GenAI model, attackers can infer its architecture and parameters, allowing them to replicate the model for their own purposes. This is a direct theft of significant R&D investment.
- Extract Training Data: Certain prompt injection techniques can trick a model into revealing parts of its underlying training data. If this data contains sensitive data or proprietary information, the consequences can be severe.
- Poison Model Outputs: Malicious agents can flood a GenAI API with biased or harmful data, attempting to “poison” the model and degrade the quality of its responses for legitimate users.
Imagine a healthcare company that has trained a GenAI model on sensitive patient data to assist doctors with diagnoses. A successful GenAI API scraping attack could not only expose that sensitive data but also compromise the integrity of the diagnostic tool, putting patient safety at risk.
Why Traditional Defenses Are Failing
How are these sophisticated attacks succeeding? The reality is that traditional security tools were not built for this fight. Perimeter-based defenses like Web Application Firewalls (WAFs) and API gateways primarily rely on signature-based detection and traffic analysis. They look for known bad patterns, high-volume requests, or suspicious IP addresses.
An advanced automated agent evades these controls with ease.
- It uses legitimate user credentials, often hijacked via a malicious browser extension.
- It operates at a “low and slow” pace, making its activity indistinguishable from normal user behavior.
- It routes traffic through residential proxies, so every request appears to come from a different, valid source.
These agents don’t trigger the classic alarms because they operate from within the trusted environment of an authenticated user’s browser session. The security perimeter has effectively shifted from the network edge to the individual browser, and most organizations lack any meaningful visibility or control at this critical layer.
The Solution: Browser Detection and Response
To combat a threat that originates in the browser, the defense must also reside in the browser. This is the principle behind LayerX’s Enterprise Browser Extension. Instead of trying to block malicious traffic at the network gate, LayerX provides deep visibility into the browser session itself, analyzing script behavior and data flows in real time to detect and neutralize threats that WAFs and other network tools can’t see.
Here’s how this approach directly counters the threat of AI scraping:
- Behavioral Analysis: LayerX doesn’t rely on outdated signatures. It analyzes the behavior of every script executing within the browser. When an automated agent begins systematically traversing a web application’s DOM or attempting to exfiltrate data, its behavior deviates from normal human patterns. LayerX detects this anomalous activity instantly and can terminate the script before any sensitive data is lost.
- Protection for Shadow SaaS: Employees constantly use unsanctioned SaaS applications (Shadow IT), creating a massive security blind spot. Since LayerX operates at the browser level, it protects the user regardless of what website they visit or what application they use. It can prevent an agent from scraping data from a corporate Salesforce instance just as effectively as it can from a personal ChatGPT account accessed on a company device. This provides critical shadow IT protection.
- Preventing GenAI-Powered Exfiltration: By monitoring all data transfers originating from the browser, LayerX can identify and block attempts to send large volumes of sensitive data to unauthorized destinations, including the APIs of public GenAI platforms. This prevents both accidental and malicious data leaks, securing corporate intellectual property in the age of AI.
The battle against AI scraping will not be won at the network perimeter. It will be won by securing the primary point of interaction between users and applications: the browser. By shifting security to this critical endpoint, organizations can finally gain the upper hand against the new generation of intelligent, automated threats.
