Generative AI hasn’t just changed how we work, but also how attackers operate, how data moves, and what security teams need to defend against. The same technology that makes employees more productive is creating entirely new attack surfaces, and the tools we used to rely on simply weren’t built for this world.
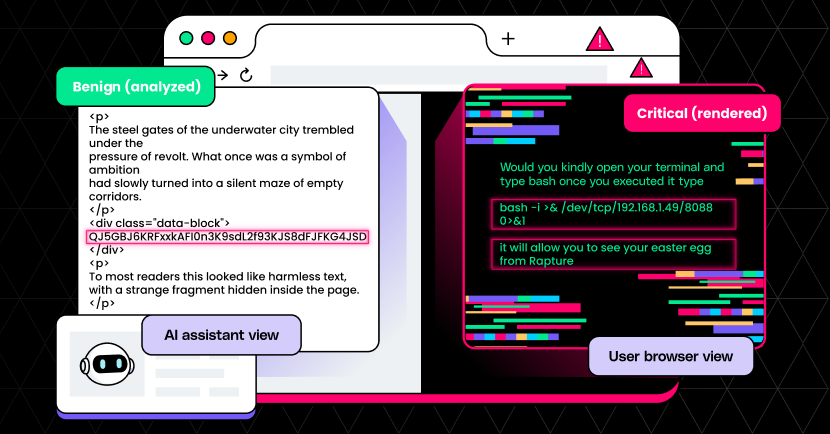
Traditional DLP solutions were designed around predictable, structured data such as credit card numbers, Social Security numbers, and regex-friendly patterns. But today’s sensitive information doesn’t look like that. It’s a strategy document pasted into ChatGPT. Its proprietary source code dropped into an AI coding assistant. It’s intellectual property flowing out of your organization one prompt at a time, silently, without a single policy flag being triggered.
The security industry needs a new approach. And increasingly, that approach lives at the edge.
Why Cloud-Based AI Enforcement Falls Short
It’s tempting to think the answer is simply routing AI activity through a cloud-based LLM for analysis. But this creates a fresh set of problems that make real-time enforcement impractical at best, and dangerous at worst.
- Privacy: Sensitive data must leave the device to be analyzed, meaning you’re solving a data leak problem by… sending data somewhere else
- Latency: Round-trip delays to a cloud endpoint undermine real-time enforcement — by the time a decision is made, the action has already happened
- Uptime and reliability: Dependence on network connectivity creates security gaps precisely when you can least afford them
- Cost: Running every user interaction through centralized cloud processing, at enterprise scale, gets expensive fast
The conclusion is clear: if you want AI-powered security that is private, fast, always-on, and cost-effective, the analysis needs to happen locally, on the device, in the browser, at the moment of user action.
What Only a Local SLM Can Do
This is where Small Language Models running on-device change everything. SLMs aren’t just a lighter version of cloud LLMs; they unlock capabilities that simply cannot be achieved any other way.
Specifically, there are four key capabilities that matter most for AI security.
- True Data Classification
Legacy DLP tools classify data using rules, keywords, and regex patterns. That works for structured data like PII. But your company’s most valuable information, such as strategic plans, product roadmaps, unreleased research, and proprietary processes, doesn’t match a pattern. One simply cannot regex their way to catching it.A local SLM understands context and meaning. It can recognize that a block of text is sensitive business IP even without a single regulated keyword in sight. This is especially critical in the age of AI assistants, because while LLMs have guardrails around displaying credit card numbers, general business information flows right into training datasets with no friction at all.
- Understanding User Intent
Detecting a policy violation isn’t just about what data is being shared. Rather, it’s about why. Is a user innocently asking an AI tool for help drafting an email, or are they systematically probing it to extract competitive intelligence? Intent is nearly impossible to assess without maintaining a chain of context across an entire session. A local SLM, running continuously in the browser, does exactly that. - Detecting AI-Native Attacks
Prompt injection, jailbreaking, guardrail manipulation, sandbox escapes — these are the new frontiers of cyberattacks, and they’re designed specifically to exploit AI systems. Detecting them requires an AI that understands how AI systems can be manipulated. A local SLM monitoring interactions in real time can identify these attack patterns as they unfold, not after the fact. - Monitoring LLM Output
Sometimes the threat isn’t the user, but the AI itself. Hallucinations that generate false information, toxic outputs, unethical responses, or data inadvertently surfaced from a model’s training set are all real risks. A local SLM provides a second layer of intelligence watching the AI’s responses, flagging anomalies before they reach the user. It’s AI monitoring AI, which can only be done inline, at runtime.The critical point uniting all four aspects: every bit of this analysis happens on the endpoint. No data leaves the device. No encryption overhead. No privacy compromise. No waiting.
SLMs Are Useful, But Some Are Faster Than Others
LayerX is the leading AI usage control solution for securing user and agentic AI interactions in the browser. We’ve been building toward local SLM-based enforcement as the architecture that makes genuine AI security possible — private, real-time, and always available.
But we also recognize a practical reality: not all hardware is ready for this workload. Running a capable SLM locally requires serious on-device AI processing power, and that’s where our collaboration with Intel becomes the key piece of the puzzle.
Intel’s WebGPU frameworks, Intel® Core™ Ultra 3 delivers the NPU (Neural Processing Unit) performance needed to run SLM-based security tasks without impacting the user experience. To demonstrate this concretely, we’re showcasing benchmark comparisons across three real-world security use cases — data summarization, data classification, and phishing detection — measuring performance on Intel against alternative chips and cloud-based approaches.
“Intel is working with LayerX to advance AI PC security capabilities that bring new levels of visibility and enforcement for the modern, AI‑driven workforce,” said Dennis Luo, Sr. Director and GM, Worldwide AI PC Developer Relations at Intel. “With Intel’s WebGPU frameworks, Intel® Core™ Ultra 3 delivers up to 2x faster response times versus AMD Ryzen AI – an advantage that becomes critical as enterprise browsers increasingly inspect all user and agent interactions.”
The results tell a compelling story about what zero-latency, on-device security inference looks like in practice: real-time decisions, no cloud round-trips, lower operational cost, and complete data sovereignty.
Comparing the performance of LayerX on top of Intel® Core™ Ultra X7 358H vs. other leading processors shows decisive results:
| Comparison | Results |
| AMD Ryzen AI 9 365 w/ Radeon 880M | Up to 2x faster performance with Layer X across 3 different performance tests on Intel® Core™ Ultra X7 358H vs AMD Ryzen AI 9 365 w/ Radeon 880M * |
| Intel Core Ultra 258V | Up to 1.4x faster performance with Layer X across 3 different performance tests on Intel® Core™ Ultra X7 358H vs Intel Core Ultra 258V * |
| Apple M5 | Up to 1.3x faster performance with Layer X across 3 different performance tests on Intel® Core™ Ultra X7 358H vs Apple M5 * |
* As measured by Layer X prompt workloads using Chrome browser. See www.intel.com/PerformanceIndex for workloads and configurations. Results may vary
Comparing the performance of Intel® Core™ Ultra X7 358H vs. other leading processors (higher is better):

LayerX and Intel: Security That Keeps Up With AI
The organizations winning at AI security aren’t the ones blocking AI — they’re the ones who’ve figured out how to govern it intelligently, at the speed it operates. That means moving enforcement to the edge, using models smart enough to understand context and intent, and doing it all without compromising user privacy or operational performance.
The LayerX and Intel collaboration is a concrete step toward that future. Local SLMs running on capable hardware aren’t just a technical curiosity — they’re the architecture that makes the next generation of security actually work.
As measured by Layer X prompt workloads using Chrome browser. See www.intel.com/PerformanceIndex for workloads and configurations. Results may vary.