In the past couple of years, we have witnessed unprecedented growth in cyber attacks originating from the web: phishing schemes, social engineering, malware sites and other malicious attacks. One of the main security services offered on the market nowadays for user protection against these threats is reputation-based URL filters.
Reputation-based security services determine the security level of a URL based on the domain’s reputation. These services prompt the user to defer from visiting unsafe websites by blocking connections from them at the time of the visit. However, their effectiveness has been significantly decreasing lately.
Unlabeled URLs originating from a legitimate domain could be awarded the reputation of the original domain. Phishing attacks exploit this feature and hide their malicious attacks under legitimate domains to evade security filters. This constitutes a major security breach that needs to be answered.
In this article we elaborate why and what can be done about it.
What is Reputation-based Security?
Website reputation security services protect users from malicious or inappropriate content on the internet, typically via a URL filtering solution. They determine the security level of the website based on its web reputation. Web reputation is produced by calculating different metrics such as the age and the history of the URL, IP reputation, hosting location, popularity and many more. The metrics vary slightly between the different vendors but the concept remains the same: attributing a numeric reputation to a website based on its basic telemetries.
If you’ve ever tried to access a web page at work and received a “website blocked” notification, then your company is using web filtering.
The Challenge: Phishing Attacks Easily Evade Reputation Filters
It has been repeatedly found that phishing campaigns leverage trusted sites to bypass filtering resources, in particular reputation filters. That means that when victims click on the link, there is no protective layer that prevents them from reaching the landing page.
Phishing Use Case Example
The following example helps understand the problem:
As part of our ongoing research on web-borne threats here at LayerX, we identified a phishing site under the URL: https://navarrebeach.com/wp-includes/fonts/cgi/auth/. As can be seen in the screenshot, the website is a phishing campaign disguised as a legitimate Login window. Unsuspecting users might be tempted to enter their credentials. (Note: we initially spotted this phishing site in the wild, and it was taken down several days later. This article was written before it was taken down).
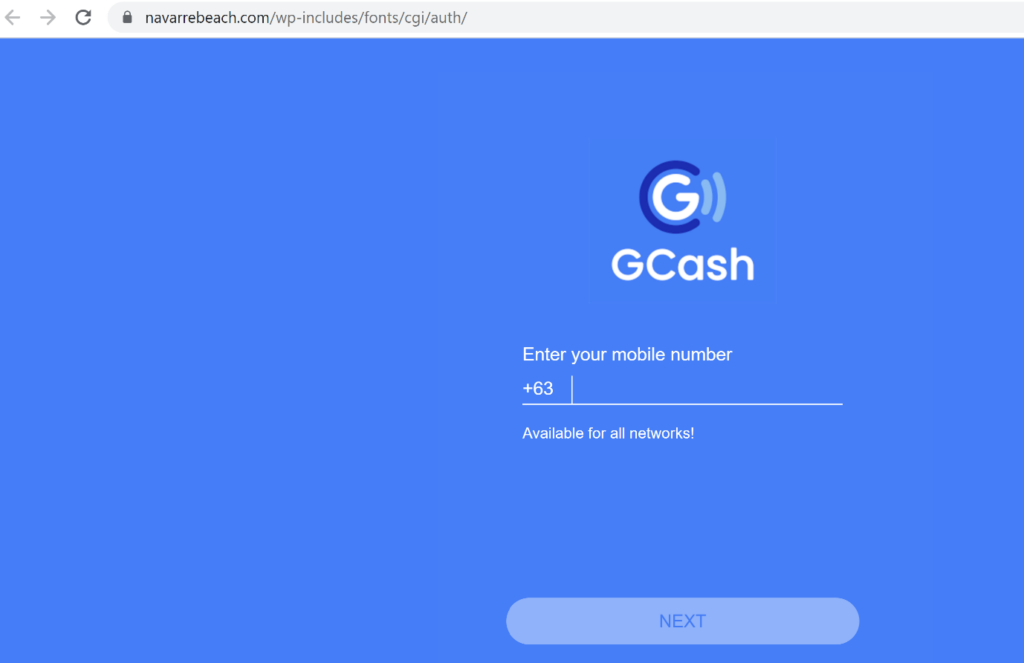
When we paste the URL into Google Chrome, no warning pops up. This means that Google Safe Browsing does not detect this site as malicious.
Perhaps a different security vendor will succeed? We checked the URL in Palo Alto Networks URL filtering, which classified the site as Low Risk, under the Travel Category.
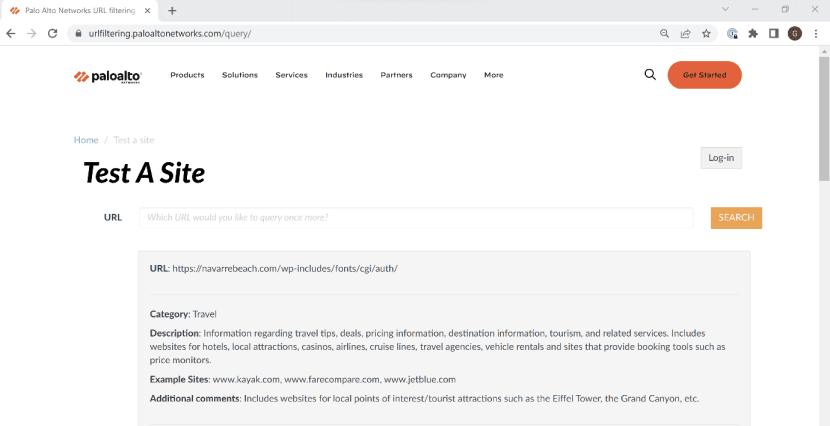
Link

We tried a third vendor – Norton Safe Web. But unfortunately, this URL filter also deemed the website safe.
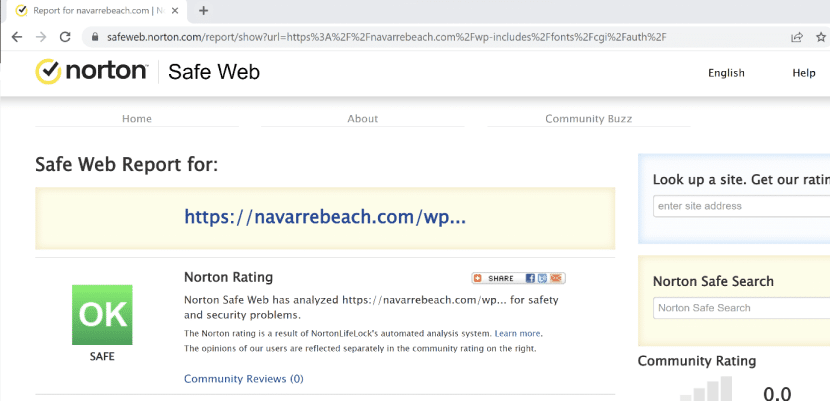
Link
Most shockingly, we scanned the URL in VirusTotal, a site that aggregates many antivirus products and online scan engines. It found that only one of 88 security vendors flagged the site as malicious (!).
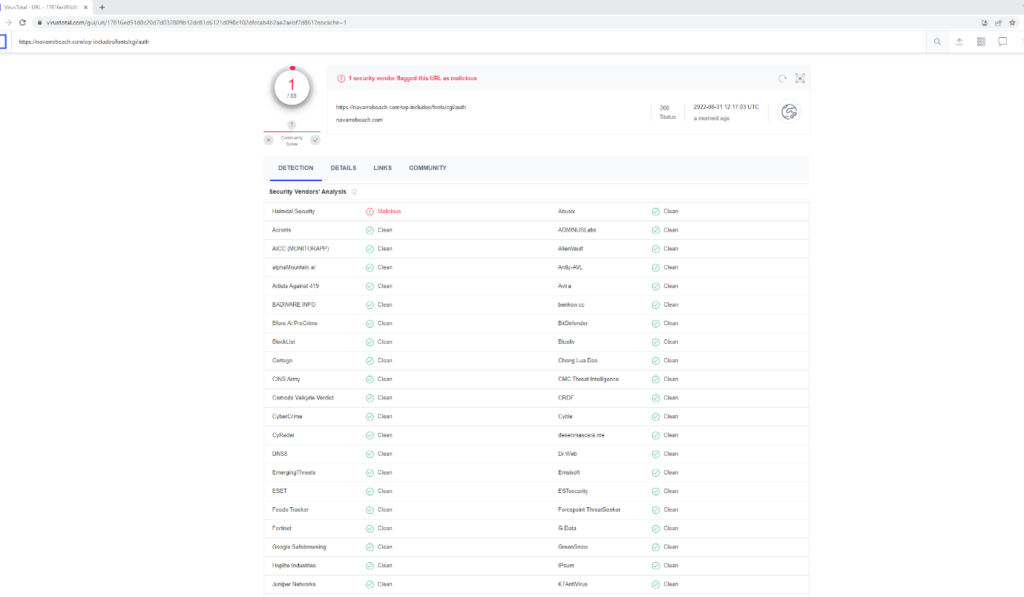
Link
What are they missing?
Why was this phishing site classified as safe? The reason is that the original website with the same domain had a good web reputation. As can be seen in this screenshot from SimilarWeb, the Navarre Beach website has a global rank, a credible category and a legitimate industry classification. All these indicate that the original website probably had a good-enough reputation, enough to not be flagged as dangerous.

Consequently, the phishing site bypassed the filters rather easily by exploiting the reputation of the previous domain it hosted. We can see that the original site indeed was a legitimate site, advertising tourist attractions in Navarre Beach, FL:

Link
We presume the original site was breached or alternatively the domain was bought and reused for the phishing campaign. Either way, the problem remains: the phishing attack snuck by unnoticed.
As the 2022 Data Breach Investigations Report by Verizon points out, phishing campaigns are still a prominent threat. Existing attacksareis most likely a harbinger for many more phishing attacks to come. Therefore, a novel approach is required for tackling the problem.
How to Identify Phishing Websites That Exploit Reputable Domains
Existing URL filters fail because they rely mainly on telemetries about the domain. But what if the website’s content could also be analyzed, alongside the site metadata?
Malicious phishing sites have distinct characteristics that appear in the site itself such as: faulty links, spelling mistakes, a malfunctioning UI, links redirecting to other malicious sites, potential .exe files pending download, and so forth. Analyzing the actual content of the site can give a better indication of whether a site is malicious or not.
It is recommended to find an automated solution that can conduct this type of analysis. Often, phishing sites are so sophisticated they will even confuse alert users. Software, on the other hand, can pick up on other indicators embedded in the website, as detailed above.
By using contextual analysis LayerX managed to successfully detect the Navarra Beach website as a malicious phishing attack. This ability is derived from thoroughly analyzing the website code and metrics derived from the website content itself, along with cutting-edge machine learning processes. This data is available to LayerX through the browser extension, before the user is impacted at all. These additional layers of security, which can add to conventional URL filters, help us stay one step ahead of phishing attacks, instead of it being the other way around.