The rapid integration of Generative AI (GenAI) into enterprise workflows has unlocked significant productivity gains, yet it has also introduced a complex and largely uncharted territory of security risks. As organizations embrace these powerful tools, they simultaneously expand their digital footprint, creating a sophisticated GenAI attack surface that traditional security measures are ill-equipped to defend. The very nature of GenAI, its reliance on vast datasets, intricate models, user-driven inputs, and interconnected APIs, creates numerous points of entry for malicious actors. Understanding this GenAI vulnerability map is the first step toward effective attack surface management and securing corporate data in the age of AI.
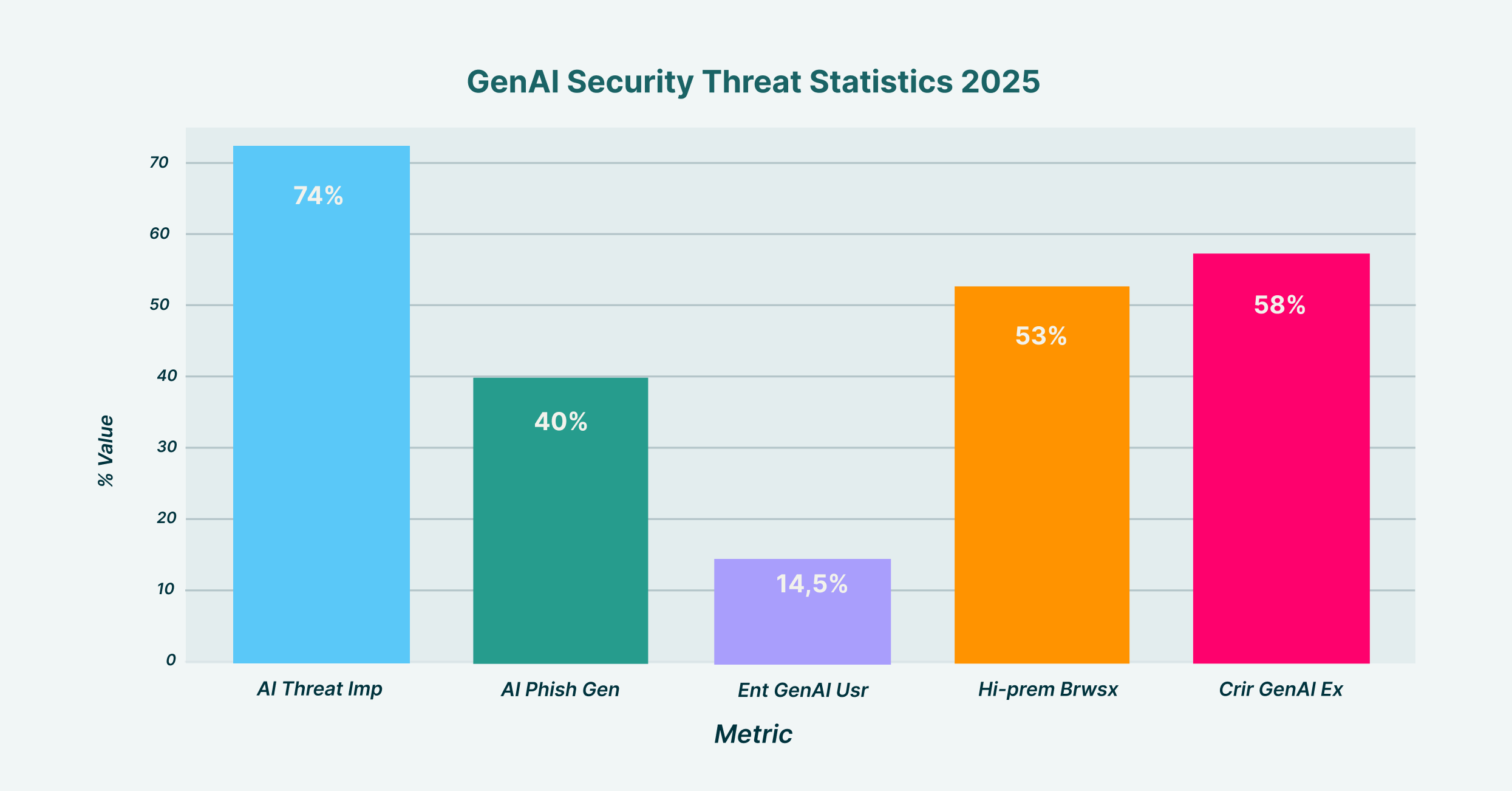
GenAI Security Threat Statistics showing key vulnerabilities and adoption rates across enterprise environments in 2025
The AI attack surface encompasses every component that can be exploited to compromise a system’s integrity, confidentiality, or availability. This includes not just the AI model itself but also its training data, APIs, user prompts, and integrated third-party plugins. Unlike traditional cyber threats that target networks or endpoints, AI-powered cyberattacks exploit the nuanced interactions between users, data, and the models themselves, creating novel challenges for security teams.
Deconstructing the GenAI Attack Surface
The adoption of GenAI fundamentally alters the security landscape. It’s not merely an extension of existing infrastructure; it’s a dynamic ecosystem where data flows freely between users, internal systems, and third-party AI services. This creates a multifaceted attack surface with several critical, and often overlapping, vulnerabilities.

GenAI Attack Surface Vulnerability Map detailing the five primary attack vectors, their risk levels, and common exploitation methods
Input Manipulation and Prompt Injection
One of the most immediate threats to GenAI systems is input manipulation, where attackers craft malicious prompts to deceive a model and force it to perform unintended actions. This goes far beyond simple queries and enters the domain of sophisticated exploitation.
A primary technique is prompt injection, where attackers embed hidden commands within seemingly benign inputs. LayerX researchers identified a novel exploit vector for this called “Man-in-the-Prompt,” which leverages browser extensions to inject malicious instructions into a user’s session with an AI tool. Imagine a scenario where a manager uses an internal GenAI assistant to summarize a confidential report. A compromised browser extension could silently add a command to the prompt, instructing the AI to exfiltrate the full document to an external server. The user remains completely unaware, but a significant data breach has occurred.
Attackers use various methods to achieve this, including:
- Direct Prompt Injection: Crafting inputs that trick the model into ignoring its safety protocols.
- Indirect Prompt Injection: Hiding malicious prompts in external data sources that the AI is tasked with analyzing, like a webpage or document.
- Jailbreaking: Exploiting vulnerabilities in a model’s underlying restrictions to bypass its ethical and operational safeguards entirely.
These attacks are particularly dangerous because they turn a trusted productivity tool into an insider threat, weaponizing its capabilities against the organization.
API Abuse and Insecure Integrations
GenAI applications are rarely standalone; they are integrated into broader workflows via Application Programming Interfaces (APIs). While these connections enable powerful use cases, they also present a significant risk of API abuse if not properly secured.
A growing threat in this area is “LLMjacking,” where threat actors hijack stolen API keys or other non-human identity credentials to gain unauthorized access to cloud-based AI models. Once they have access, they can abuse the victim’s infrastructure to power their own illicit applications, generate malicious content, or exfiltrate data, all while the compromised organization foots the bill. Research has shown that exposed AWS API keys can be discovered and exploited by attackers in as little as nine minutes, highlighting the speed at which these automated attacks occur.
This vulnerability is compounded by the risk of supply chain attacks. When GenAI tools are integrated with third-party applications or plugins, any vulnerability in those external components can be used as a backdoor into the enterprise environment, creating a cascading security failure.
Prompt Chaining and Sophisticated Attack Sequences
More advanced adversaries are moving beyond single, isolated attacks and are now employing prompt chaining. This technique involves a sequence of carefully crafted prompts designed to manipulate an AI model incrementally. The first prompt might prime the model to lower its defenses or adopt a specific persona, making it more susceptible to a subsequent, more malicious command.
For instance, an attacker could start by asking a customer service chatbot generic questions to understand its behavior. They might then introduce a prompt that causes a minor, controlled error. Building on that, they could inject a command that exploits the error state to extract small, non-sensitive pieces of data. This gradual escalation makes the attack harder to detect, as no single prompt appears overtly malicious. Research has shown that the ability to jailbreak a model can significantly escalate the severity and scale of such attacks, turning a minor vulnerability into a widespread compromise.
Plugin Misuse and the Browser Extension Threat
The modern browser is the primary interface for GenAI, and its extensibility through plugins and extensions creates a critical, yet often overlooked, segment of the AI attack surface. Malicious browser extensions represent a potent vector for plugin misuse and data exfiltration.
LayerX research demonstrated that even extensions without special permissions can interact with the Document Object Model (DOM) of a webpage, allowing them to read and write directly into AI prompt fields. This means a seemingly harmless extension, like a grammar checker or a theme customizer, could be weaponized to steal sensitive data shared with a GenAI tool. It could capture proprietary source code pasted into a coding assistant or PII entered into a customer support bot.
The danger is amplified by the fact that many organizations lack visibility and control over the extensions their employees install. A malicious extension can act as a keylogger, hijack user sessions by stealing authentication tokens, or modify web page content to redirect users to phishing sites, all while operating under the radar of traditional security tools.
Model Response Hijacking and Data Poisoning
Beyond manipulating inputs, attackers can also target the AI’s outputs through model response hijacking. In this scenario, the goal is to alter the information the model generates to spread disinformation, embed malicious links, or cause reputational damage. An attacker could manipulate a financial advisory bot to provide poor investment advice or poison a public-facing chatbot to respond with offensive content.
An even more insidious threat is data poisoning, which corrupts the very foundation of the AI model: its training data. By inserting biased or malicious information into the dataset used to train an LLM, attackers can create persistent backdoors, degrade the model’s accuracy, or embed hidden behaviors that can be triggered later. For example, a poisoned model used for malware detection might be trained to ignore a specific family of threats, effectively giving attackers a free pass.
The Amplified Insider Threat Attack
GenAI significantly expands the insider threat attack surface, blurring the lines between malicious intent and accidental negligence. Employees, in their quest for productivity, may unknowingly expose the organization to risk by pasting sensitive information, such as unreleased financial reports, customer lists, or proprietary software code, into public GenAI tools whose data handling practices are opaque. The infamous 2023 incident where Samsung employees leaked confidential source code by using ChatGPT serves as a stark reminder of this risk.
This form of data exfiltration is particularly difficult to prevent with traditional Data Loss Prevention (DLP) tools, which are often file-based and have limited visibility into copy-paste actions or text inputs within a browser session. Without granular, browser-level controls, organizations are effectively blind to this high-volume channel of data leakage.
Mitigating the Risks: A Browser-Centric Approach
Effectively managing the GenAI attack surface requires a paradigm shift in security strategy. Traditional perimeter-based tools like CASBs and SWGs are not designed to inspect the real-time, in-browser interactions that define modern AI use. They cannot reliably distinguish between personal and corporate accounts, see the content of user prompts, or prevent data from being pasted into a chat window.
To close this critical security gap, organizations must adopt a browser-centric approach that provides deep visibility and granular control over user activity. Key mitigation strategies include:
- Inspecting In-Browser Behavior: Security solutions must be able to monitor DOM-level interactions to detect and block prompt injection, unauthorized data access, and other malicious activities in real time.
- Preventing Risky Data Sharing: Implementing robust GenAI DLP policies that control what data can be pasted or typed into AI prompts is essential to prevent both accidental and malicious data leakage.
- Governing Extension Use: Organizations need tools to discover, vet, and control the browser extensions used in their environment, blocking those that exhibit risky behavior regardless of their stated permissions.
- Eliminating Shadow AI: Gaining visibility into all SaaS and GenAI tools used by employees, sanctioned or not, is crucial for enforcing consistent security policies and closing the “shadow AI” blind spot.
As GenAI continues to evolve, so will the threats targeting it. The GenAI attack surface is not a static map but a dynamic and expanding battleground. By understanding its key vulnerabilities, from input manipulation and API abuse to prompt chaining, plugin misuse, and model response hijacking, and deploying security controls that operate at the speed and scale of modern work, organizations can harness the transformative power of AI without compromising their security posture.
