The integration of Generative AI into enterprise workflows has unlocked unprecedented productivity. From drafting emails to analyzing complex datasets, these tools are reshaping how businesses operate. However, this efficiency comes at a cost, introducing a new and complex set of security challenges. For Chief Information Security Officers (CISOs) and IT leaders, the central conflict is clear: how do you enable your workforce to use these powerful tools without exposing the organization to catastrophic data leakage? This introduces significant AI data privacy concerns that cannot be ignored. The very nature of Large Language Models (LLMs), which process and learn from user inputs, creates a direct channel for sensitive corporate data to be exfiltrated, often without any malicious intent from the employee.
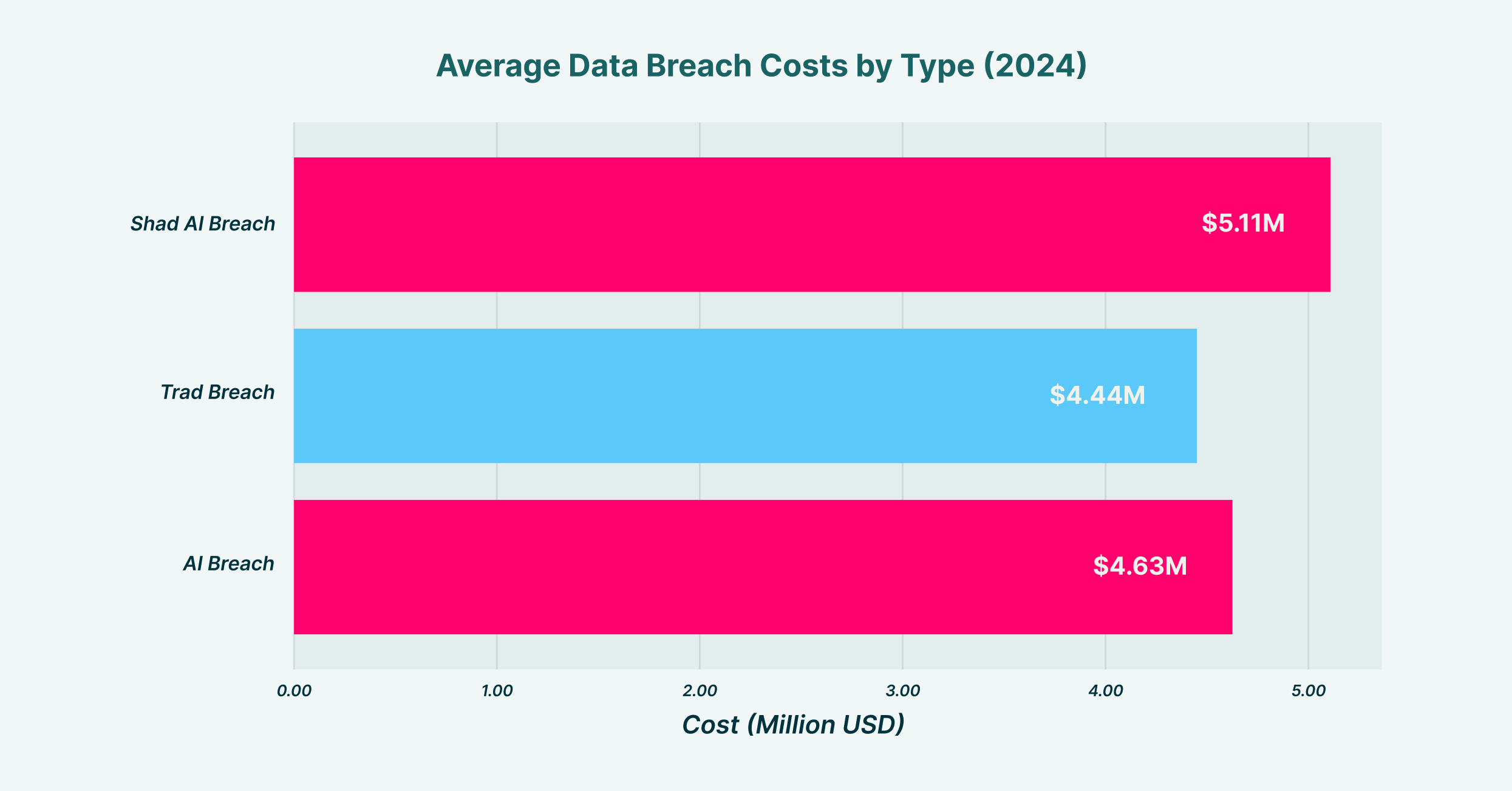
Average data breach costs showing AI-related incidents cost significantly more than traditional breaches
Understanding the intersection of AI and data privacy is no longer optional; it’s a core component of modern cybersecurity strategy. The ease with which employees can copy and paste proprietary code, customer PII, or internal financial data into a public GenAI platform presents a critical vulnerability. This article explores the specific generative AI data privacy risks, examines the pressing compliance gaps under regulations like GDPR, HIPAA, and CCPA, and outlines actionable strategies for securing your organization in the age of AI.
The Mechanics of Data Exposure in Generative AI
To grasp the full scope of AI data privacy risks, it’s essential to understand how these models handle information. The problem isn’t just about one-time data entry; it’s about the lifecycle of that data once it leaves your controlled environment. When an employee submits a prompt containing sensitive information, two primary risks emerge. First, the data could be used to train future versions of the model. Many public GenAI tools include clauses in their terms of service that grant them the right to use user inputs for model refinement. This means your confidential business strategies or customer data could become embedded within the model itself, potentially accessible to other users in future responses.
This scenario highlights one of the most significant AI data collection privacy risks: the unintentional contribution of proprietary data to a third-party intelligence pool. Imagine a developer pasting a snippet of proprietary source code into a GenAI tool to debug it. That code, once processed, might be absorbed by the LLM. Later, a user from a competitor company, asking for a similar function, could be presented with a response generated from your unique code. This form of data leakage is subtle, difficult to track, and poses a direct threat to intellectual property. The second major risk involves the prompt history itself. If an employee’s account is compromised or if the GenAI provider suffers a data breach, every query ever entered could be exposed. This creates a detailed log of sensitive activities, from drafting confidential legal documents to analyzing internal employee performance data, all available to an attacker.
A Deeper Look at Generative AI Data Privacy Concerns
The potential for data exfiltration is not a single, monolithic threat. It manifests in several ways, each posing unique challenges for security teams. The most immediate of the data privacy issues with AI is inadvertent data sharing by well-meaning employees. They aren’t trying to cause harm; they are simply trying to be more efficient. An analyst might use a GenAI tool to summarize a report containing non-public financial information, or a marketing manager might upload a list of customer email addresses to draft a targeted campaign. In their view, they are just using a tool. In reality, they are performing a high-risk data transfer outside the organization’s security perimeter.
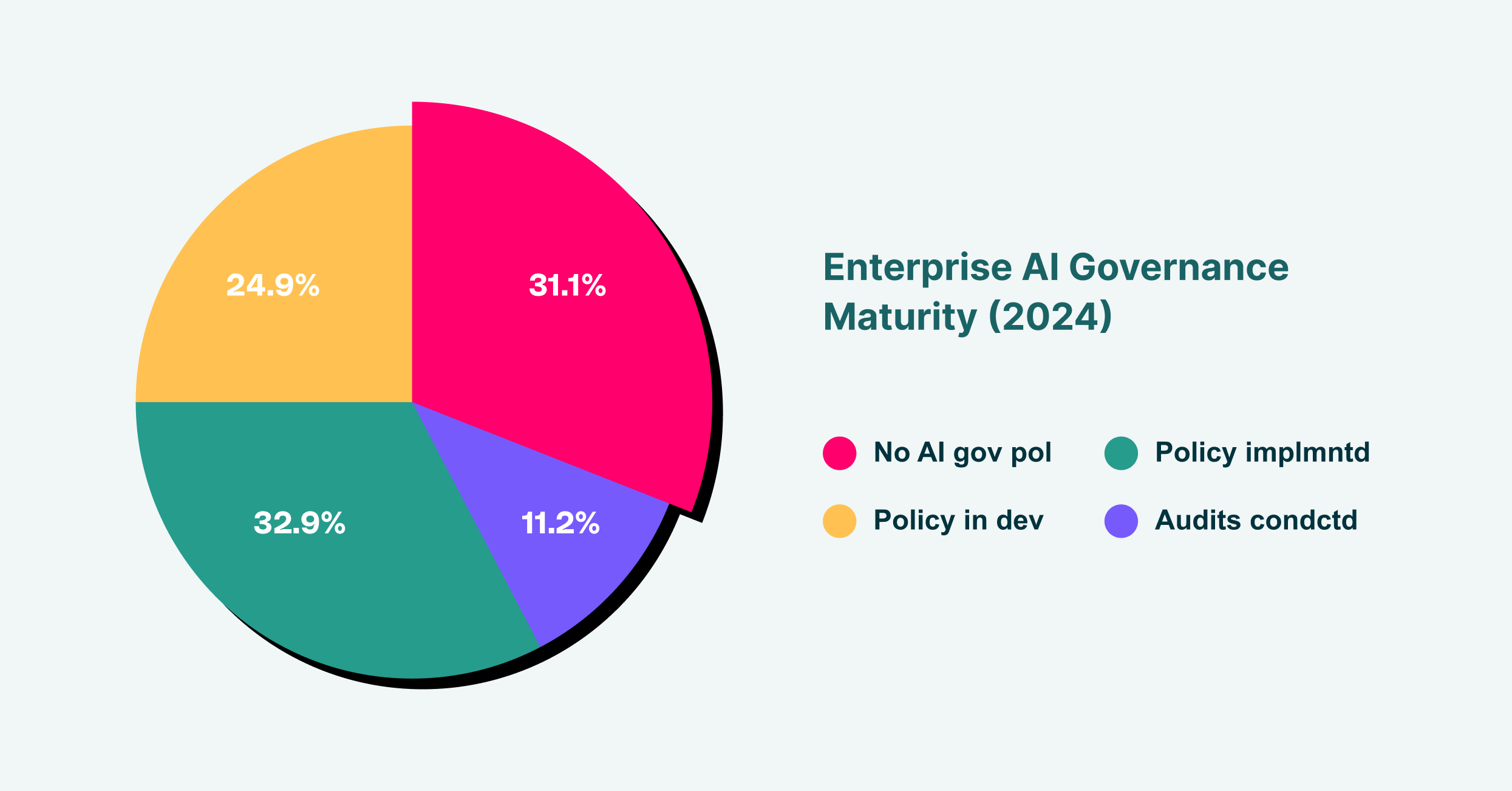
Distribution of AI governance maturity across enterprises, showing most organizations lack comprehensive AI oversight
Another critical issue is the rise of “Shadow AI”; the unsanctioned use of GenAI applications by employees. While the IT department may have vetted and approved a specific enterprise-grade AI tool, employees will inevitably turn to other, more convenient public platforms. This creates massive visibility gaps. Security teams cannot protect what they cannot see, and without a comprehensive audit of all SaaS and AI usage across the enterprise, it’s impossible to enforce security policies effectively. These unmonitored channels become prime vectors for data leakage, completely bypassing existing Data Loss Prevention (DLP) controls. These AI data privacy issues are compounded by the fact that traditional security solutions, like network-based firewalls or CASBs, often lack the granularity to distinguish between sanctioned and unsanctioned AI usage within the browser, where these activities primarily occur.
The Tangled Web of GenAI Compliance
Navigating the regulatory landscape is one of the most complex aspects of managing GenAI use. The core principles of major data privacy laws were established long before the widespread adoption of LLMs, creating significant GenAI compliance challenges. These frameworks are built on concepts of data minimization, purpose limitation, and user consent; principles that are often at odds with how GenAI models operate.
Consider the General Data Protection Regulation (GDPR). It grants EU citizens the “right to be forgotten” (Article 17), allowing them to request the deletion of their personal data. How does an organization comply with this request if an employee has already pasted that citizen’s data into a third-party LLM? It’s often impossible to trace and delete that specific data point once it has been absorbed into the model’s training set. A single prompt can, therefore, place an organization in breach of GDPR, risking fines of up to 4% of its global annual turnover. The lack of transparency into how and where data is stored by GenAI providers makes demonstrating compliance nearly impossible.
| Regulation | Data Protected | Maximum Penalty |
| GDPR | Personal data of EU residents | €20M or 4% global revenue |
| HIPAA | Protected Health Information | $1.5M per violation |
| CCPA | California residents’ personal info | $2,500 per consumer |
Regulatory compliance requirements showing the significant financial exposure from data privacy violations
Similarly, the Health Insurance Portability and Accountability Act (HIPAA) in the United States imposes strict rules on the handling of Protected Health Information (PHI). If a healthcare professional uses a public GenAI tool to summarize patient notes or draft a communication, they are transmitting PHI to a non-compliant third party, constituting a clear HIPAA violation. The California Consumer Privacy Act (CCPA) presents its own set of challenges, requiring businesses to be transparent about the data they collect and how it’s used. The opaque nature of many AI models makes it difficult to provide the clear disclosures required by law, further complicating the compliance picture.
Can AI Be Part of the Solution?
While the challenges are significant, it’s also worth noting the developing role of AI in data privacy protection. This may seem paradoxical, but AI-powered tools are also being engineered to identify and classify sensitive data, detect anomalous user behavior, and automate threat responses. For example, machine learning algorithms can be trained to recognize patterns consistent with data exfiltration, such as a user suddenly attempting to upload a large volume of PII to a web service. These systems can provide real-time alerts that allow security teams to intervene before a major breach occurs.
Furthermore, AI can help organizations map their data landscape, identifying where sensitive information resides across sprawling networks and cloud applications. This automated discovery and classification is a foundational step in any robust data protection strategy. By using AI to fight AI-exacerbated risks, organizations can build a more dynamic and responsive security posture. However, relying on these solutions alone is insufficient. Protection must be pushed as close to the source of the risk as possible: the user’s browser, where the interaction with GenAI tools actually happens.
A Proactive Approach to AI Security with LayerX
The core of the problem lies at the intersection of the user, the browser, and the web application. This is where data exposure occurs, and it’s where security controls must be enforced. LayerX directly addresses the most pressing generative AI data privacy concerns by providing granular visibility and control over all user activity within the browser, without requiring the installation of another intrusive agent. By focusing on the browser as the critical point of interaction, LayerX can effectively distinguish between safe and risky behaviors within any web or SaaS application, including GenAI platforms.
LayerX allows organizations to map all GenAI usage across the enterprise, shining a light on Shadow AI and providing a comprehensive inventory of which tools are being used by whom. From there, security teams can implement risk-based governance policies. For instance, a policy could be set to prevent users from pasting any data classified as PII or “Confidential” into a public GenAI tool, while still allowing them to use the tool for non-sensitive tasks. This granular control ensures that productivity is not hindered, but risk is actively managed. If a user attempts a high-risk action, LayerX can either block the action entirely or display a customized warning message, educating the user on corporate policy in real-time. This approach helps to prevent both inadvertent and malicious data leakage at its source, closing the compliance gaps left open by traditional security solutions and directly mitigating the primary AI data privacy threats facing the modern enterprise.
