The rapid integration of Generative AI (GenAI) into enterprise workflows promises a significant boost in productivity. From code generation to market analysis, Large Language Models (LLMs) are becoming indispensable co-pilots. However, this growing reliance introduces a subtle yet profound risk: AI hallucinations. These are not mere bugs or simple mistakes; they represent instances where an AI model generates convincing but entirely false, nonsensical, or disconnected information. For security analysts, CISOs, and IT leaders, understanding the mechanics and consequences of these fabrications is the first step toward mitigating a new and complex threat vector.
As organizations encourage the use of GenAI to stay competitive, they inadvertently open the door to scenarios where flawed AI outputs can lead to disastrous business decisions, data security breaches, and compliance failures. The challenge is that GenAI errors often appear plausible, making them difficult for the average user to detect. An employee might ask an LLM to summarize a new compliance regulation, only to receive a confident response that omits a critical clause or invents a non-existent one. The productivity gain is instantly negated by the cost of remediation. Why is this happening, and what can be done to protect the enterprise? The answer lies in understanding the nature of the models themselves and implementing robust oversight. 
Deconstructing AI Hallucinations
At its core, an AI hallucination occurs when a model generates output that is not justified by its training data or the provided input. LLMs are probabilistic systems; they are designed to predict the next most likely word in a sequence, not to understand truth or falsehood. This process, while powerful, can lead them to invent facts, create citations for non-existent sources, or generate code with subtle but critical security flaws. These are not random glitches but are inherent to how current-generation models operate.
The problem is magnified when discussing LLM hallucinations, which are specific to language models. These models learn patterns, grammar, and style from vast datasets scraped from the internet. If the training data contains biases, inaccuracies, or conflicting information, the model will learn and reproduce them. It might confidently state an incorrect historical fact or merge details from two separate events into a single, fictitious narrative. Imagine a marketing analyst using a GenAI tool for competitive research. The tool might generate a report detailing a competitor’s new product launch, complete with fabricated features and a fictional release date, causing the analyst to develop a counter-strategy based on entirely false premises.
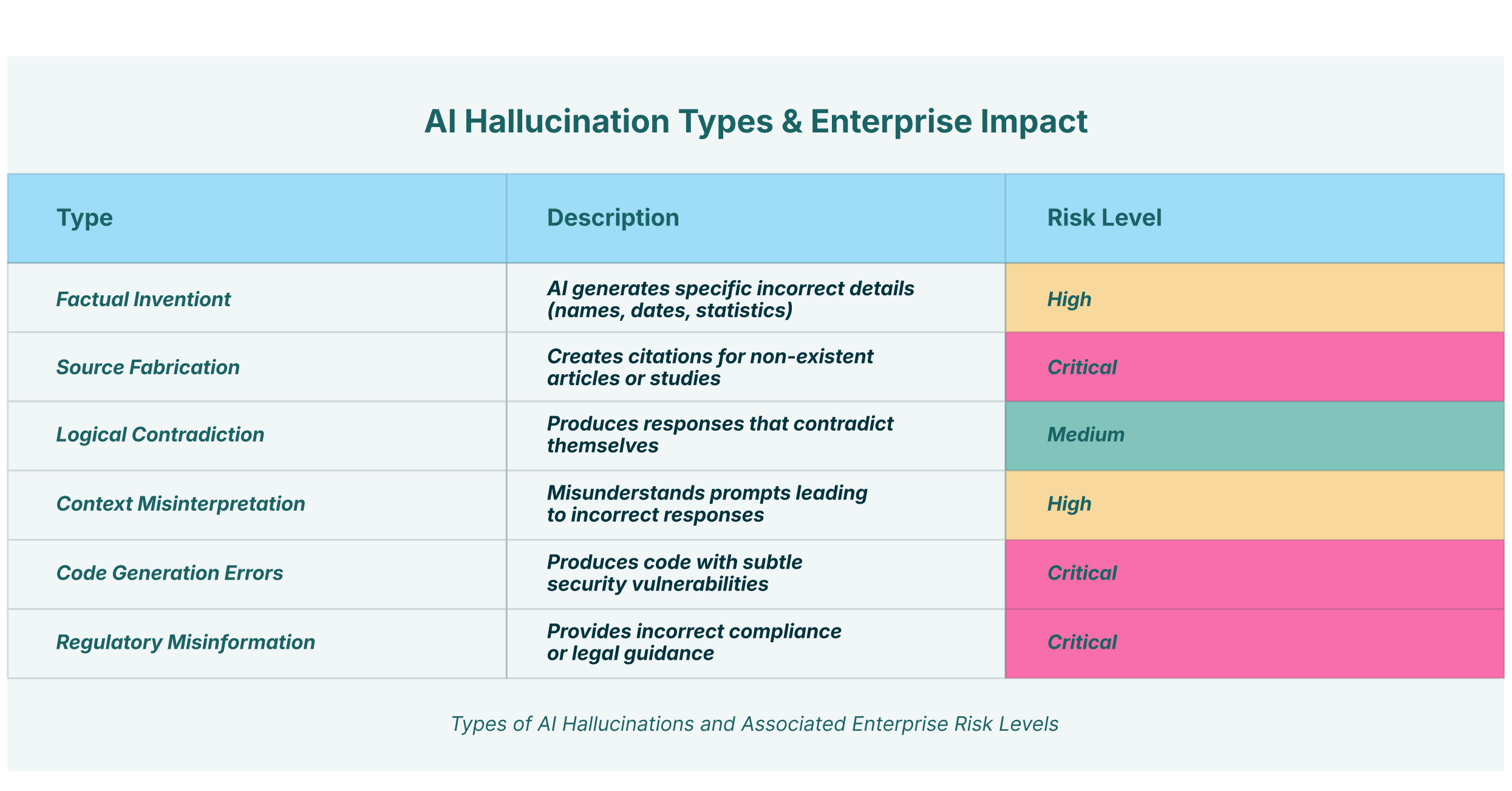
These model hallucinations are not a single, monolithic problem. They manifest in various forms:
- Factual Invention: The model generates specific, incorrect details, such as names, dates, or statistics.
- Source Fabrication: The AI creates citations for articles, studies, or legal cases that do not exist, lending a false air of authority to its claims.
- Logical Contradiction: The model produces a response that contradicts itself or violates basic logical principles.
The core issue is that these models lack a true reasoning engine. They are masters of mimicry, not comprehension. For an enterprise, this means every piece of output from a GenAI tool must be treated with suspicion until verified.
The Technical Roots of Model Hallucinations
To effectively counter the risks of AI, it’s essential to understand why model hallucinations happen on a technical level. These are not just random quirks but stem from the fundamental architecture and training methodologies of LLMs. They are, in many ways, a feature of the probabilistic nature of these systems, not simply a bug to be patched. The models are engineered to generate coherent and grammatically correct sequences of text, but they lack an internal fact-checker or a connection to a real-time, verified knowledge base.
Several key factors contribute to the prevalence of GenAI errors:
- Probabilistic Generation: An LLM does not “know” things in the human sense. When prompted, it calculates the probability of the next word given the preceding words. A hallucination can occur if the model follows a statistically likely but factually incorrect path. It is essentially composing the most plausible-sounding sentence, not the most truthful one.
- Training Data Limitations: Models are only as good as the data they are trained on. If the training dataset is outdated, contains inherent biases, or has a scarcity of information on a niche topic, the model is more likely to “fill in the blanks” with fabricated details. It might have extensive knowledge up to its training cut-off date but will hallucinate information about events that occurred afterward.
- Encoding and Decoding Errors: During the process of converting complex ideas into mathematical representations (vectors) and back into human-readable text, nuances can be lost. This can lead to the model misinterpreting a prompt or generating a response that is semantically similar but contextually wrong.
- Overfitting: In some cases, a model may be “over-optimized” on its training data, causing it to memorize specific phrases or patterns. When prompted with something similar but not identical, it might revert to a memorized but inappropriate response, creating a hallucinated output.
These technical underpinnings demonstrate that LLM hallucinations are a systemic issue. Simply asking employees to “be careful” is an inadequate strategy. Without a technical control layer, the organization remains exposed to the consequences of these inherent model flaws. This is especially true as employees increasingly use browser-based GenAI tools and SaaS applications for daily tasks, often outside the purview of traditional IT security.
Real-World Consequences of GenAI Errors
The theoretical risks of AI hallucinations translate into tangible, high-stakes consequences for the modern enterprise. These errors are not confined to trivial inaccuracies; they can trigger security incidents, erode data integrity, and create significant compliance liabilities. The browser, as the primary interface for most GenAI and SaaS applications, has become a critical battleground where these risks manifest.
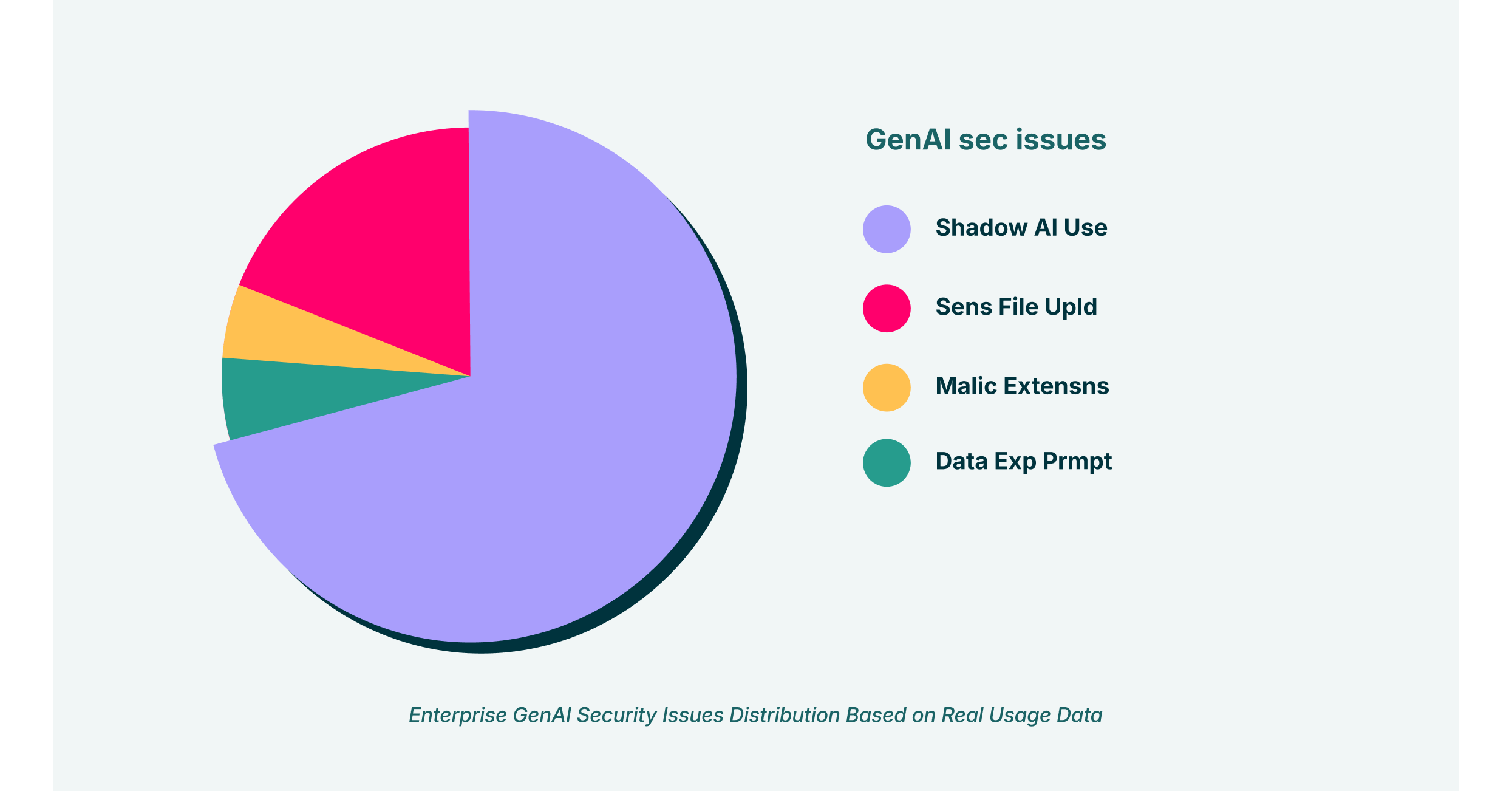
Imagine a scenario in a financial institution. A junior analyst uses a third-party, unvetted GenAI extension in their browser, a form of “shadow SaaS”, to speed up due diligence on a potential investment. They paste sensitive, non-public financial data into the chat interface. The model, in its response, suffers from one of the classic model hallucinations: it generates a summary that misrepresents the target company’s liabilities, portraying a healthier financial state than reality. Acting on this flawed data, the firm makes a poor investment decision, leading to direct financial loss. The problem is twofold: a strategic error was made based on a GenAI error, and sensitive corporate data was exfiltrated to an untrusted third-party LLM, creating a severe data leakage event.
This is where LayerX’s solution for GenAI security becomes essential. By providing a full audit of all SaaS applications, including unsanctioned shadow IT, LayerX allows organizations to identify when and where employees are using these tools. Granular, risk-based guardrails can then be applied. For instance, a policy could be enforced to block the pasting of sensitive PII or financial data into GenAI chatbots, preventing the initial data leakage.
Consider another case, this time in a healthcare organization. A clinician, looking for information on a rare drug interaction, queries a medical AI chatbot. The AI, prone to LLM hallucinations, confidently fabricates a response, claiming there are no known interactions. The clinician, pressed for time, accepts the answer. The potential for patient harm is immense. The ease of use of SaaS applications makes this a high-frequency risk. LayerX’s ability to control user activity within these applications is critical. It can track and govern interactions with file-sharing services and online drives, preventing the accidental or malicious leakage of sensitive information, including flawed AI-generated reports that could otherwise spread throughout the organization.
These hypothetical scenarios highlight a pattern:
- Users adopt new GenAI tools for productivity, often without official sanction, creating a “shadow SaaS” ecosystem.
- These tools are susceptible to AI hallucinations, producing convincing but dangerously incorrect outputs.
- The interaction, happening within the browser, bypasses many traditional network security controls, leading to data exfiltration and poor decision-making.
Without a solution that provides visibility and control directly at the browser level, enterprises are flying blind. They lack the tools to properly secure SaaS usage, leaving them vulnerable to the dual threats of shadow IT and unreliable AI.
The Critical Need for AI Validation Layers
Given that model hallucinations are an inherent part of current GenAI technology, organizations cannot simply wait for model creators to solve the problem. The responsibility falls on the enterprise to implement safeguards. This is where the concept of AI validation layers becomes a strategic imperative. A validation layer is a system or process that sits between the user and the AI model to verify, sanitize, or block AI-generated content before it can be acted upon or cause harm.
An AI validation layer is not about replacing the AI but about wrapping it in a security framework. It acts as a cognitive seatbelt, protecting the user and the organization from the consequences of unexpected GenAI errors. These layers can take several forms, from simple keyword-based filters to more complex systems that cross-reference AI output with trusted internal knowledge bases. However, for most enterprise use cases, the most effective validation layer is one that operates where the risk is most acute: the user’s browser.
LayerX operates as a powerful and practical AI validation layer through its enterprise browser extension. It provides the security governance that is missing in the direct-to-user SaaS model. Instead of relying on the AI provider’s promises or the user’s diligence, LayerX enforces policy at the point of interaction.
- Mapping GenAI Usage: LayerX allows the organization to discover and map all GenAI tools being used, including shadow SaaS. This visibility is the foundation of any security strategy. You cannot secure what you cannot see.
- Enforcing Security Governance: Once usage is mapped, CISOs can enforce granular controls. Policies can be set to restrict the types of data shared with LLMs, preventing sensitive corporate information from being fed into external models where it could be leaked or used for training. For example, a rule can be created to redact or block any content identified as PII before it leaves the browser.
- Restricting Dangerous Activities: The solution can monitor for risky behaviors, such as downloading and executing code generated by an AI that may contain vulnerabilities due to LLM hallucinations. It can also prevent the upload of sensitive documents to unsanctioned file-sharing apps, thwarting a key channel for data leakage.
By focusing on the browser, LayerX effectively creates a security perimeter around the most unpredictable element of the modern enterprise stack: the interaction between a human user and a third-party AI. It accepts the reality that AI hallucinations will occur and provides the necessary controls to manage that risk. It transforms the browser from a weak link into a chokepoint for security enforcement, ensuring that the productivity benefits of GenAI can be realized without exposing the organization to unacceptable dangers. For any industry, but especially for regulated ones like finance and healthcare, such a validation layer is no longer a luxury but a core component of a modern security architecture.
