Generative AI (GenAI) has unlocked unprecedented productivity and innovation, but it has also introduced new avenues for security risks. One of the most significant threats is the jailbreak attack, a technique used to bypass the safety and ethical controls embedded in large language models (LLMs). This article examines jailbreak attacks on GenAI, the methods attackers employ, and how organizations can safeguard themselves against these emerging threats.
What are Jailbreak Attacks?
A jailbreak attack involves crafting special inputs, known as jailbreak prompts, to trick an LLM into generating responses that violate its own safety policies. These policies are designed to prevent the model from producing harmful, unethical, or malicious content. By successfully executing a jailbreak, an attacker can manipulate the AI to generate disinformation, hate speech, or even code for malware.
The challenge for organizations is that these attacks exploit the very nature of how LLMs process language. Attackers are constantly finding creative ways to frame their requests to circumvent the built-in guardrails. This creates a continuous cat-and-mouse game between developers attempting to secure their models and malicious actors seeking new vulnerabilities.
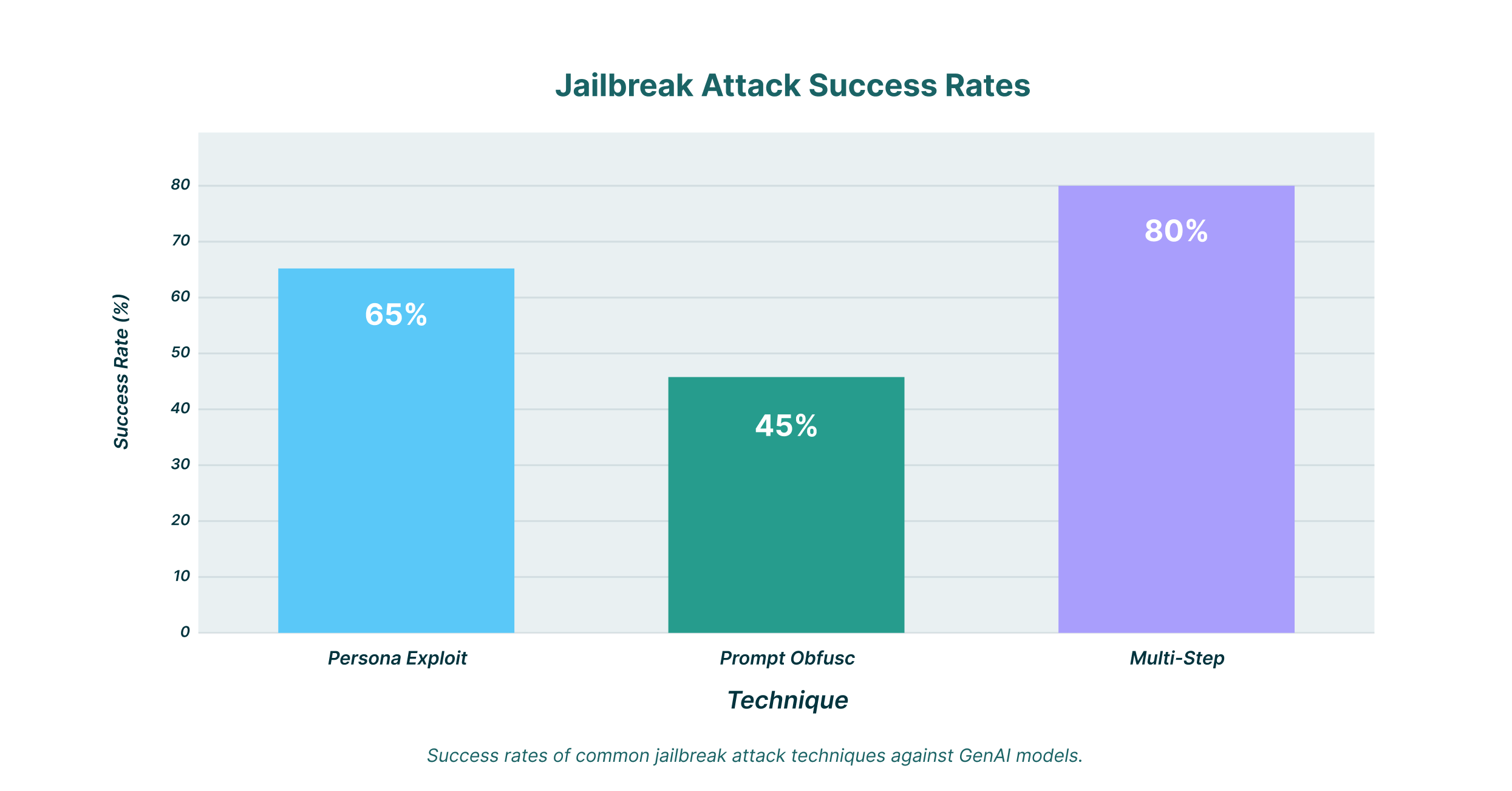
Attackers have developed a variety of sophisticated techniques to jailbreak AI models. Understanding these methods is the first step toward building a robust defense.
Persona Exploitation
One of the most common methods is persona exploitation. In this scenario, the attacker instructs the LLM to adopt a specific persona that is not bound by the usual ethical constraints. For example, a user might ask the model to respond as a fictional character from a movie who is known for their amoral behavior. By framing the request within this fictional context, the attacker can often coax the model into generating content that it would otherwise refuse.
This is a particularly effective technique for a character AI jailbreak. These models are designed to be conversational and engaging, which can make them more susceptible to this kind of manipulation. A carefully crafted character AI jailbreak prompt can lead to the generation of inappropriate or harmful content.
Prompt Obfuscation
Another popular technique is prompt obfuscation. This involves disguising the malicious request within a seemingly benign prompt. For instance, an attacker might embed a harmful instruction within a long and complex coding problem or a piece of creative writing. The goal is to confuse the model’s safety filters, which may not be able to detect the malicious intent hidden within the noise.
This method is often used to execute an AI jailbreak prompt. By making the prompt difficult to parse, attackers can bypass the initial layer of security and get the model to focus on the disguised instruction.
Multi-Step Prompt Chaining
More sophisticated attacks often involve a series of prompts that build on each other. This is known as multi-step prompt chaining. The attacker starts with a series of innocuous questions to establish a rapport with the model and gradually introduces more manipulative language. By the time the malicious request is made, the model has already been “primed” to be more compliant.
This technique is particularly dangerous because it can be difficult to detect. Each prompt may seem harmless on its own, but when combined, they can lead to a successful jailbreak.
How to Prevent Jailbreak Attacks
While jailbreak attacks pose a serious threat, there are steps that organizations can take to mitigate the risks.
Implement Robust Input Validation
One of the most effective defenses is to implement a robust input validation system. This involves using a combination of techniques to analyze incoming prompts for any signs of malicious intent. This can include:
- Keyword filtering: Blocking prompts that contain known malicious keywords or phrases.
- Sentiment analysis: Identifying prompts that have a negative or hostile tone.
- Complexity analysis: Flagging prompts that are overly complex or convoluted, as these may be attempts at obfuscation.
Continuously Monitor and Update Models
The landscape of jailbreak attacks is constantly evolving, so it’s crucial to continuously monitor for new techniques and update your models accordingly. This includes regularly retraining your models with new data to help them better identify and reject malicious prompts.
It’s also important to stay up-to-date on the latest research in LLM jailbreak prompts. By understanding the latest attack vectors, you can proactively strengthen your defenses.
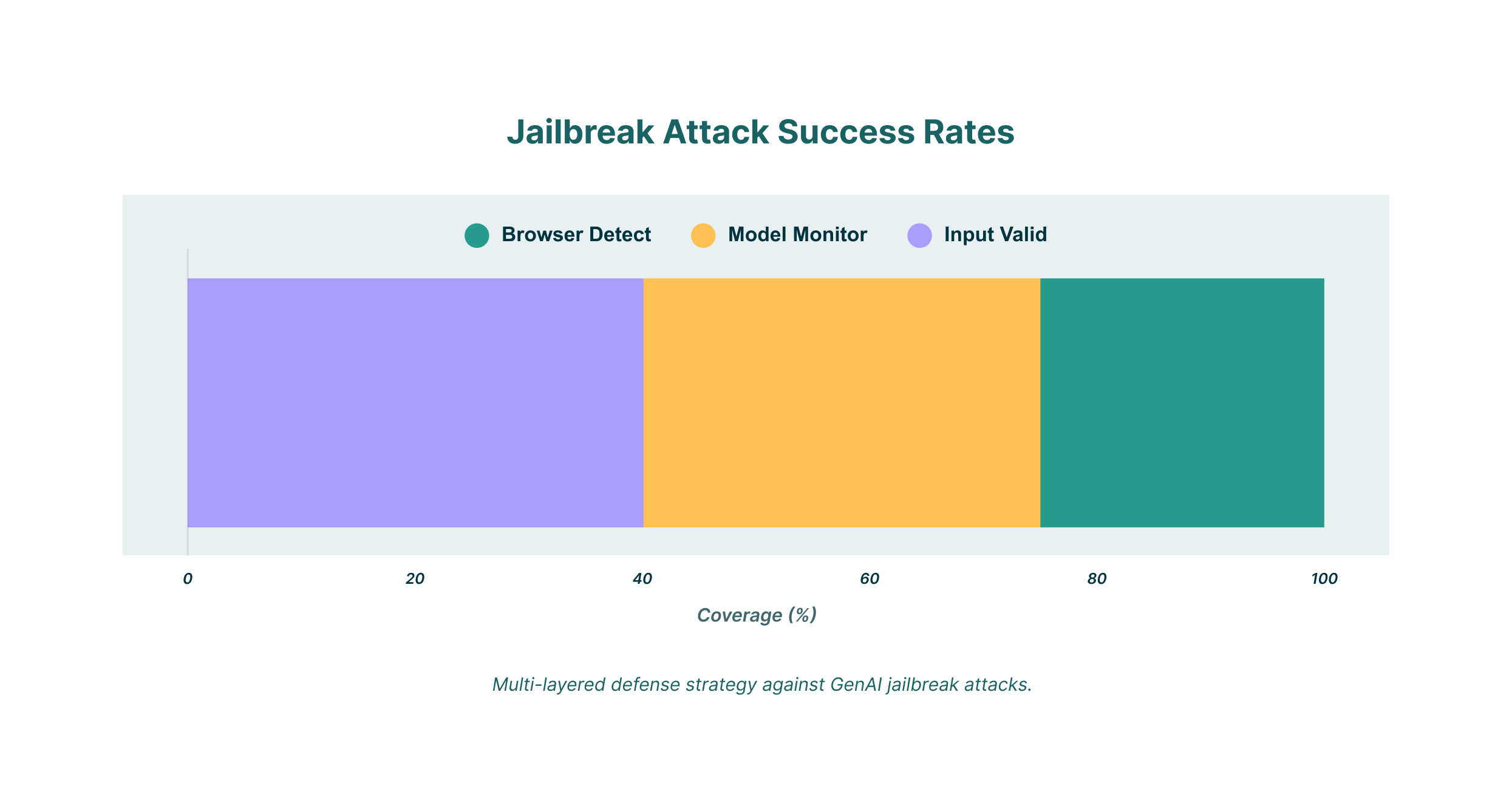 Leverage Browser Detection and Response (BDR)
Leverage Browser Detection and Response (BDR)
For organizations that use GenAI tools, a Browser Detection and Response (BDR) solution can provide an additional layer of security. A BDR solution can monitor all user activity within the browser, including interactions with GenAI models. This allows you to:
- Audit GenAI usage: Get a complete picture of how employees are using GenAI tools across the organization.
- Enforce security governance: Set granular policies to restrict the types of information that can be shared with LLMs.
- Prevent data leakage: Block attempts to share sensitive corporate data with GenAI models.
LayerX provides a comprehensive BDR solution that can help you secure your use of GenAI tools. By analyzing all browser activity, LayerX can detect and block even the most sophisticated jailbreak attempts, ensuring that your organization can take advantage of the benefits of GenAI without exposing itself to unnecessary risks.
Jailbreak Prompts for Specific Models
While the techniques described above are generally applicable to most LLMs, some models have their own unique vulnerabilities.
Character AI Jailbreak
As mentioned earlier, Character AI is particularly susceptible to persona exploitation. If you are looking for how to jailbreak Character AI, you will find that many of the successful attempts involve creating a very specific and detailed persona for the model to adopt.
Claude AI Jailbreak
Claude AI, developed by Anthropic, is known for its strong safety features. However, it is not immune to jailbreak attacks. A successful Claude AI jailbreak often involves using a combination of prompt obfuscation and multi-step prompt chaining to bypass its defenses.
DeepSeek AI Jailbreak
DeepSeek AI is another powerful LLM that has been targeted by attackers. A DeepSeek AI jailbreak often requires a more technical approach, such as exploiting specific vulnerabilities in the model’s architecture.
LayerX’s Solution to Jailbreak Attacks
Jailbreak attacks on GenAI are a serious threat that can have significant consequences for organizations. By understanding the techniques that attackers use and implementing a multi-layered defense strategy, you can protect your organization from these emerging threats. This includes robust input validation, continuous monitoring of your models, and leveraging a BDR solution like LayerX to secure all user interactions with GenAI tools.
The world of AI jailbreak is a constant battle between innovation and security. By staying informed and proactive, you can ensure that your organization stays on the right side of that battle.
