Machine learning models are no longer just analytical tools. They are the engines driving decision-making across the modern enterprise. This reliance has birthed a sophisticated threat vector known as adversarial AI attacks. These are not traditional software exploits that target code vulnerabilities like buffer overflows. They are optical illusions for algorithms.
Anatomy of an Attack: How Models Are Deceived
Attackers use subtle inputs to deceive AI systems into making incorrect classifications or revealing sensitive training data. For security leaders in 2025, the stakes have shifted. We are witnessing a transition from theoretical research to active weaponization. Attackers are operationalizing these techniques to bypass fraud detection and manipulate financial algorithms.
They also exfiltrate proprietary data through the very tools employees use daily. The browser has become the primary staging ground for these incursions. It is the interface where employees paste sensitive code into LLMs and where malicious extensions can silently inject toxic prompts. Understanding the mechanics of adversarial attacks on AI is the first step in securing the browser-to-cloud attack surface.
Adversarial inputs often look like noise to a human observer but are interpreted as distinct signals by a neural network. This discrepancy allows attackers to manipulate outcomes without triggering traditional security alerts. The methods used to execute AI adversarial attacks generally fall into three distinct categories.
Data Poisoning: Corrupting the Well
Poisoning attacks occur during the training or fine-tuning phase. By injecting malicious samples into the dataset, an attacker can create a hidden backdoor in the model. An attacker might subtly alter a set of phishing emails in a training corpus. The resulting spam filter learns to classify specific malicious patterns as benign.
In the context of GenAI, this is particularly dangerous. If an enterprise fine-tunes a coding assistant on internal repositories that have been subtly tampered with, the consequences are severe. The model may suggest insecure code snippets to developers, effectively automating the introduction of vulnerabilities.
Model Evasion: The Digital Sleight of Hand
Evasion attacks happen at inference time. The attacker modifies the input data to cause the model to misclassify it. This is the most common form of adversarial attacks on AI seen in the wild today. A classic example involves altering a few pixels in an image of a stop sign.
The autonomous vehicle creates a dangerous classification error and identifies it as a speed limit sign. In the corporate environment, evasion techniques are used to bypass malware classifiers. This allows weaponized files to slip past next-generation antivirus solutions.
Model Extraction and Theft
Model stealing involves an attacker probing a “black box” AI system with numerous queries. Their goal is to reconstruct the underlying model or extract the private data it was trained on. By analyzing the outputs, they can build a surrogate model that mimics the proprietary behavior of the target.
This steals intellectual property. It also provides a sandbox for the attacker to test future evasion attacks offline. They can ensure their methods will work against the production system without alerting the victim.
The Increase of Automated Threats in 2025
The barrier to entry for executing these attacks has lowered significantly. Automated toolkits now allow even low-skilled actors to launch sophisticated campaigns. The sheer volume of incidents is tracking upward aggressively. Security teams must rethink their defensive posture.
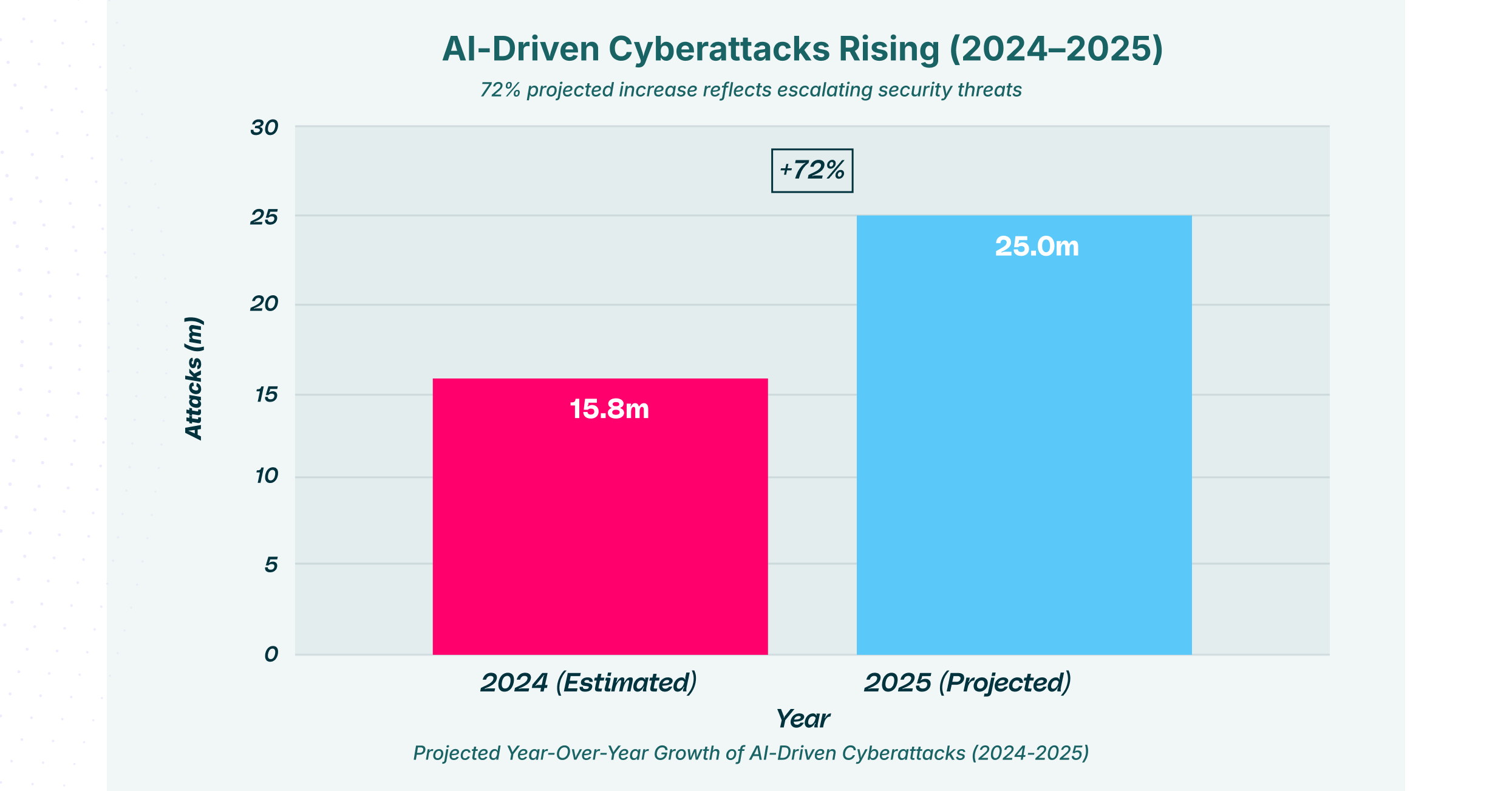
This chart illustrates the projected 72% year-over-year surge in global cyber incidents. As organizations deploy more models, the volume of AI adversarial attacks is expected to reach unprecedented levels, with 28 million incidents projected for 2025. This exponential growth highlights how automated tools are lowering the barrier to entry for threat actors executing adversarial AI attacks at scale.
This surge is not random. It is driven by the widespread adoption of open-source AI tools that can be repurposed for offense. Attackers are utilizing GenAI to automate the discovery of vulnerabilities in other AI systems. This creates a loop of adversarial optimization that moves faster than human defenders can patch.
Weaponizing GenAI: The Phishing Epidemic
Generative AI has fundamentally changed the social engineering game. Adversarial attacks in generative AI are not just about tricking a model. They are about using the model to trick humans. Attackers now deploy Large Language Models (LLMs) to craft contextual, grammatically perfect phishing emails.
These emails mimic the tone and style of internal executives. The effectiveness of these AI-driven campaigns is alarming when compared to traditional methods.
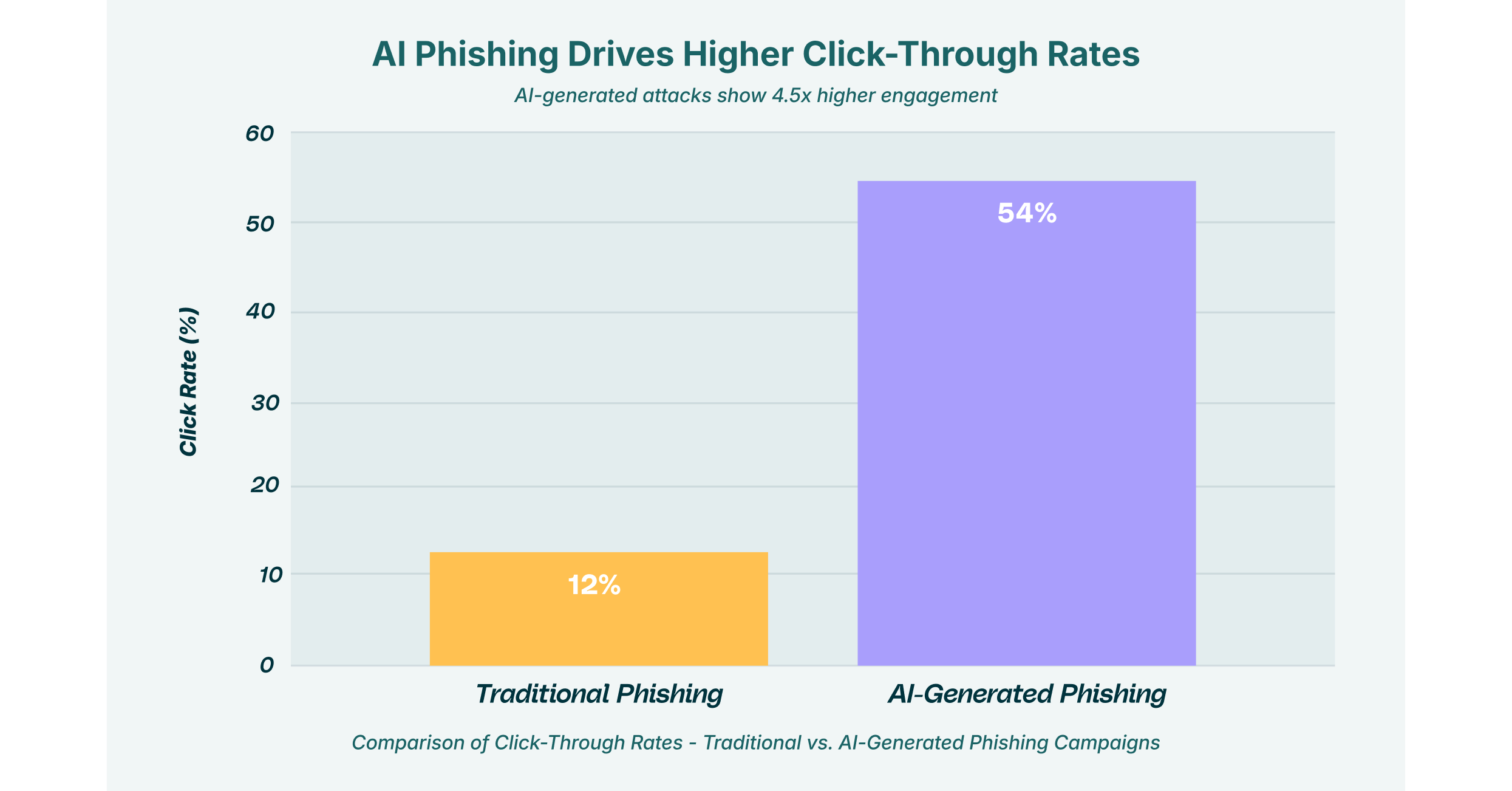
A comparison of click-through rates reveals the dangerous efficacy of adversarial attacks in generative AI. While traditional phishing campaigns struggle with a 12% success rate, AI-generated lures, crafted to mimic trusted internal communications, achieve a staggering 54% click-through rate. This data underscores the critical need for specialized browser security to detect the subtle linguistic and structural anomalies of GenAI-powered social engineering.
Browser security solutions must now evolve beyond simple URL filtering. They need to analyze the intent and context of the content being rendered. When an employee interacts with a GenAI chatbot or receives a suspicious email, the browser extension serves as the critical control point. It can flag anomalies that suggest the content was synthetically generated to deceive.
Prompt Injection: The “SQL Injection” of the AI Era
One of the most pervasive forms of adversarial attacks in generative AI is prompt injection. This technique involves crafting a text input that overrides the model’s original instructions. It forces the system to perform unauthorized actions.
Mechanisms of Injection
The risk is not limited to users typing bad things into a chat box. The real danger lies in indirect prompt injection, or “Man-in-the-Prompt” attacks. In this scenario, an LLM might process a webpage or a document that contains hidden malicious instructions.
LayerX Labs has identified vectors where malicious browser extensions feed these toxic prompts into enterprise LLMs. This happens without the user’s consent. This allows attackers to manipulate the output of trusted AI tools. It effectively turns a helpful assistant into an insider threat.
Taxonomy of Prompt Injection Risks
| Attack Type | Mechanism | Risk Level |
| Direct Injection | Attacker manually inputs malicious prompts to bypass safety filters (Jailbreaking). | High |
| Indirect Injection | Malicious instructions are hidden in external data (e.g., webpages) consumed by the AI | Critical |
| Context Poisoning | Manipulating conversation history to influence future model responses. | Medium |
This table categorizes the primary vectors for prompt injection, a specific subset of adversarial AI attacks. Indirect injection poses a critical risk because it occurs without the user’s knowledge. It often happens through a “Man-in-the-Prompt” scenario where a browser extension reads a compromised webpage and feeds the malicious instruction into the enterprise LLM.
The Deepfake Dilemma and Identity Assurance
The same technology used to create helpful avatars is being weaponized to bypass identity verification systems. Deepfakes have graduated from internet novelties to enterprise-grade security threats.
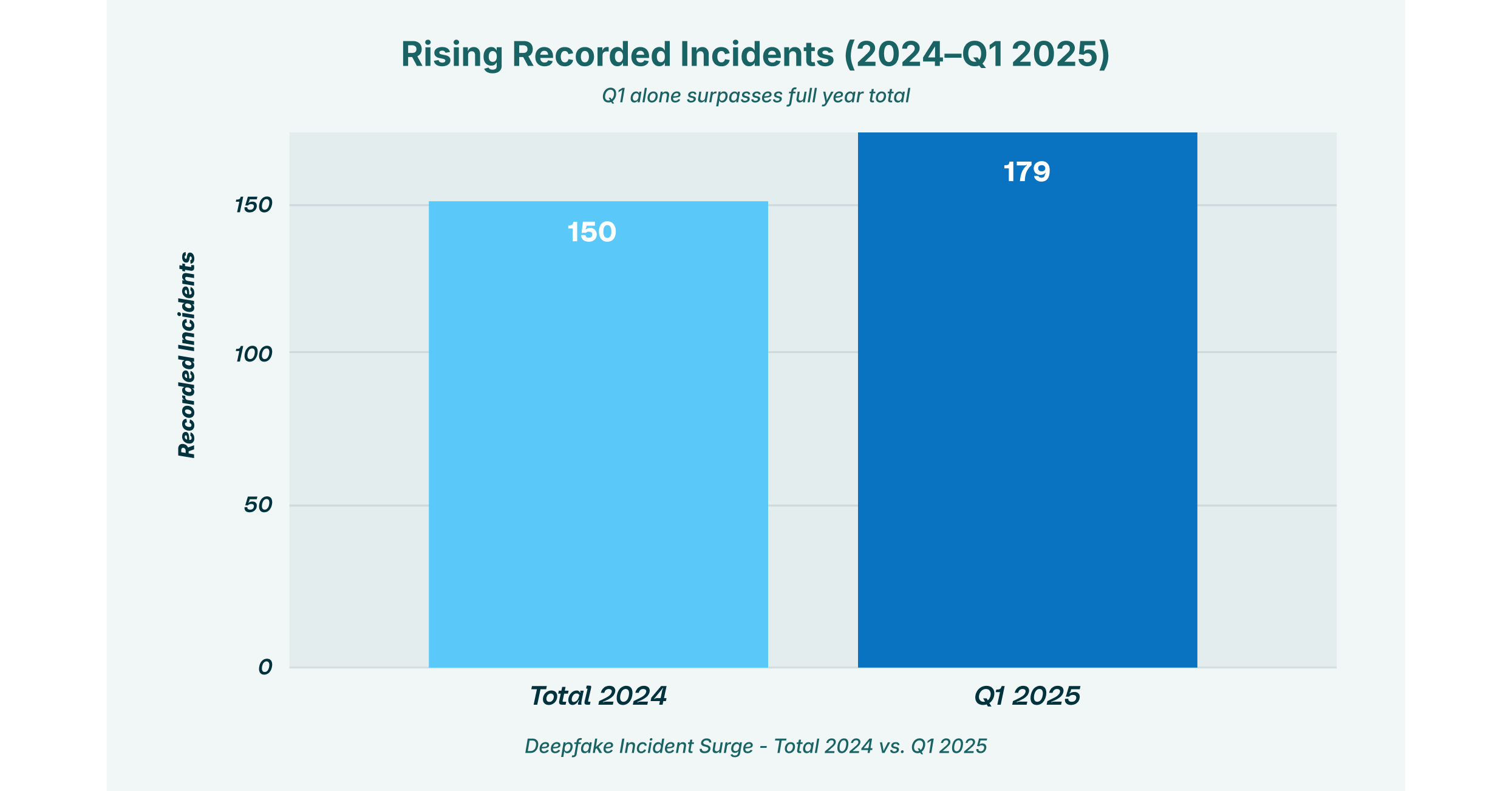 This visualization captures the explosive growth of identity-based adversarial attacks on AI. In just the first quarter of 2025, recorded deepfake incidents (179) already surpassed the total for the entire previous year (150). This trend indicates a strategic shift by attackers toward using GenAI to bypass biometric verification and impersonate executives in high-stakes fraud campaigns.
This visualization captures the explosive growth of identity-based adversarial attacks on AI. In just the first quarter of 2025, recorded deepfake incidents (179) already surpassed the total for the entire previous year (150). This trend indicates a strategic shift by attackers toward using GenAI to bypass biometric verification and impersonate executives in high-stakes fraud campaigns.
These attacks often manifest in video conferencing platforms or during remote onboarding processes. An attacker utilizes a real-time deepfake overlay to impersonate a CEO or a finance director. They authorize fraudulent transfers or request sensitive credentials. Organizations must deploy defenses that can detect the digital artifacts of synthetic media.
The Browser: The Primary Attack Surface
Why is the browser central to this discussion? Because it is the interface through which employees access GenAI tools like ChatGPT, Gemini, or Claude. It is the gateway through which AI adversarial attacks reach the endpoint.
Traditional network security tools are blind to the encrypted traffic between a user’s browser and an AI service. They cannot see if an employee is pasting PII into a chatbot. They cannot see if a “Shadow SaaS” extension is silently scraping that data. LayerX’s research into “Shadow AI” reveals that a significant percentage of enterprise data leakage occurs through unmanaged browser extensions.
When we talk about preventing adversarial attacks on AI, we must look at the browser as the enforcement point. It is the only place where we can see the user’s input, the model’s output, and the context of the web session simultaneously. This visibility allows for real-time redaction of sensitive data.
Defensive Strategies for the GenAI Era
Defending against these sophisticated threats requires a multi-layered approach. It is not enough to rely on the safety filters built into the models by vendors. Enterprises must wrap these models in their own security controls.
Red Teaming and Fuzzing
Organizations should initiate proactive stress testing of their AI deployments. Red teaming involves ethical hackers attempting to jailbreak models. They execute adversarial AI attacks to identify weaknesses.
This is often paired with fuzzing. Fuzzing is an automated technique where thousands of random or semi-random inputs are thrown at the model. The goal is to see if any cause it to crash or reveal training data.
Browser Detection and Response (BDR)
A comprehensive BDR solution acts as a firewall for the user’s web session. It can prevent the installation of malicious extensions that facilitate data poisoning or model theft.
Furthermore, it enables organizations to enforce policy controls on GenAI usage. This ensures that employees are not inadvertently participating in an attack. It prevents exposing the organization to adversarial attacks in generative AI through risky behaviors.
Securing the Future of Intelligence
The cat-and-mouse game between attackers and defenders has entered a new phase. Adversarial attacks represent a fundamental challenge to the integrity of the systems we are building for our future.
By understanding the nuances of adversarial attacks on AI, security leaders can build resilient architectures. The path forward does not require abandoning AI. It requires securing the ecosystem in which it operates.
This means recognizing that the browser is no longer just a document viewer. It is the frontline of defense against adversarial attacks in generative AI. Through rigorous testing and real-time monitoring, enterprises can navigate this complex landscape with confidence.
